Reading and Writing Time Series¶
Built-in Readers¶
Since TimeSeries and BinnedTimeSeries are subclasses of Table, they have
read() and write() methods
that can be used to read and write time series from files. We include a few readers for
well-defined formats in astropy.timeseries. For instance we have readers for
light curves in FITS format from the Kepler and TESS missions.
Example¶
In this demonstration of using Kepler FITS time series, we start off by fetching an example file:
from astropy.utils.data import get_pkg_data_filename
example_data = get_pkg_data_filename('timeseries/kplr010666592-2009131110544_slc.fits')
Note
The light curve provided here is handpicked for example purposes. To get other Kepler light curves for science purposes using Python, see the astroquery affiliated package.
This will set example_data to the filename of the downloaded file (so you
can replace this by the filename for the file you want to read in). We can then
read in the time series using:
from astropy.timeseries import TimeSeries
kepler = TimeSeries.read(example_data, format='kepler.fits')
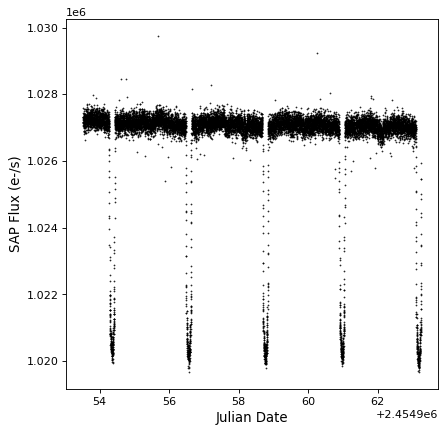
Now we can check that the time series has been read in correctly:
import matplotlib.pyplot as plt
plt.plot(kepler.time.jd, kepler['sap_flux'], 'k.', markersize=1)
plt.xlabel('Julian Date')
plt.ylabel('SAP Flux (e-/s)')
{kind=link}
{kind=link}
Reading Common Light Curve Formats¶
At the moment only a few formats are defined in astropy itself, in part
because there are not many well-documented formats for storing time series. So
in many cases, you will likely have to first read in your files using the more
generic Table class (see Reading and Writing Table Objects). In fact, the
TimeSeries.read and
BinnedTimeSeries.read methods
can do this behind the scenes. If the table cannot be read by any of the time
series readers, these methods will try to use some of the default
Table readers and then require users to specify the
names of the important columns.
Examples¶
If you are reading in a file called sampled.csv where
the time column is called Date and is an ISO string, you can do:
>>> from astropy.timeseries import TimeSeries
>>> from astropy.utils.data import get_pkg_data_filename
>>> sampled_filename = get_pkg_data_filename('data/sampled.csv',
... package='astropy.timeseries.tests')
>>> ts = TimeSeries.read(sampled_filename, format='ascii.csv',
... time_column='Date')
>>> ts[:3]
<TimeSeries length=3>
time A B C D E F G
Time float64 float64 float64 float64 float64 float64 float64
----------------------- ------- ------- ------- ------- ------- ------- -------
2008-03-18 00:00:00.000 24.68 164.93 114.73 26.27 19.21 28.87 63.44
2008-03-19 00:00:00.000 24.18 164.89 114.75 26.22 19.07 27.76 59.98
2008-03-20 00:00:00.000 23.99 164.63 115.04 25.78 19.01 27.04 59.61
If you are reading in a binned time series from a file called
binned.csv and with a column time_start giving the
start time and bin_size giving the size of each bin, you can do:
>>> from astropy import units as u
>>> from astropy.timeseries import BinnedTimeSeries
>>> binned_filename = get_pkg_data_filename('data/binned.csv',
... package='astropy.timeseries.tests')
>>> ts = BinnedTimeSeries.read(binned_filename, format='ascii.csv',
... time_bin_start_column='time_start',
... time_bin_size_column='bin_size',
... time_bin_size_unit=u.s)
>>> ts[:3]
<BinnedTimeSeries length=3>
time_bin_start time_bin_size ... E F
s ...
Time float64 ... float64 float64
----------------------- ------------- ... ------- -------
2016-03-22T12:30:31.000 3.0 ... 28.87 63.44
2016-03-22T12:30:34.000 3.0 ... 27.76 59.98
2016-03-22T12:30:37.000 3.0 ... 27.04 59.61
See the documentation for TimeSeries.read and BinnedTimeSeries.read for more details.
Alternatively, you can read in the table using your own code then construct the
TimeSeries object as described in Creating Time Series, although
then you cannot write out another time series in the same format.
If you have written a reader/writer for a commonly used format, please feel free
to contribute it to astropy!