The SQL standard has never defined if SQL identifiers (database object's names) have to be case sensitive or not, leaving that subject to each database engine implementation. All of them accept two syntaxes for SQL identifiers:
the first is if the SQL identifier is surrounded by double quotes (sometimes backquotes or other characters), usually making the SQL identifier case sensitive (and also making it possible to use reserved SQL keywords as identifiers).
the second is if it's not enquoted, usually meaning that the SQL identifier is not case sensitive.
Sometimes those rules don't apply or apply only partially. For example a MySQL server, depending on how it is configured and on what kind of OS it is running on, will have different sets of meanings for these notations.
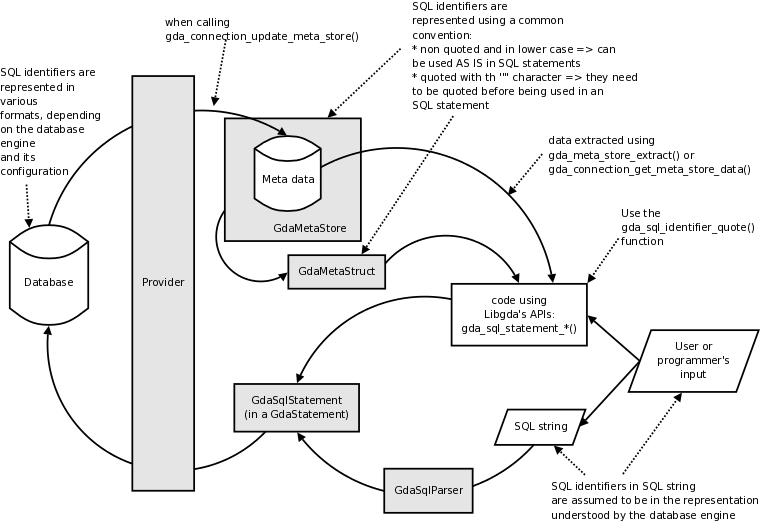
As a result, Libgda has to be the least intrusive possible when the user wants to execute an SQL statement, and lets the database being accessed apply its own rules. However Libgda features meta data information retrieval (getting the list of tables, views,...) and there some representation conventions have been fixed, see the meta data section about SQL identifiers for more information.
The following diagram illustrates how Libgda handles SQL identifiers' representations depending where they are used: