
|
Doxygen
|
The Unicode consortium has defined a set of emoji with the corresponding unicode sequences. Doxygen supports the subset of emoji characters as used by GitHub (based on the list https://api.github.com/emojis). An emoji is created using the \emoji command. For example \emoji smile (or \emoji :smile:) both produce 😄.
For the different doxygen output types there is an output defined:
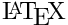 , in case the image can be found (see Emoji image retrieval) otherwise the plain emoji text (i.e.
, in case the image can be found (see Emoji image retrieval) otherwise the plain emoji text (i.e. :<text>:) is displayed:<text>:)<emoji> tag with name and unicode attributes.In the list of images can be downloaded via the following Python script:
When invoking it with the -d image_dir option the images will by downloaded in the image_dir directory. By means of the doxygen configuration parameter LATEX_EMOJI_DIRECTORY the requested directory can be selected.
For convenience a zip with the result of running the script can also be downloaded from https://www.doxygen.nl/dl/github_emojis.zip
For an overview of the supported emoji one can issue the command:
doxygen -f emoji <outputFileName>