exit to terminate the program completely. A tough way to handle a
problem if only because the destructors of local objects aren't activated.
setjmp and
longjmp to enforce non-local exits. This mechanism implements a kind
of goto jump, allowing the program to continue at an outer level,
skipping the intermediate levels which would have to be visited if a series of
returns from nested functions would have been used.
setjmp and
longjmp isn't frequently encountered in C++ (or even in C)
programs, due to the fact that the program flow is completely disrupted.
C++ offers exceptions as the preferred alternative to, e.g.,
setjmp and longjmp. Exceptions allow C++ programs to perform a
controlled non-local return, without the disadvantages of longjmp and
setjmp.
Exceptions are the proper way to bail out of a situation which cannot be
handled easily by a function itself, but which is not disastrous enough for
a program to terminate completely. Also, exceptions provide a flexible layer
of control between the short-range return and the crude exit.
In this chapter exceptions are covered. First an example is given of the
different impact exceptions and the setjmp/longjmp combination have on
programs. This example is followed by a discussion of the formal aspects
of exceptions. In this part the guarantees our software should be able
to offer when confronted with exceptions are presented. Exceptions and their
guarantees have consequences for constructors and destructors. We'll encounter
these consequences at the end of this chapter.
throw statement. The keyword
throw, followed by an expression of a certain type, throws the expression
value as an exception. In C++ anything having value semantics may be
thrown as an exception: an int, a bool, a string, etc. However,
there also exists a standard exception type (cf. section 10.8) that
may be used as base class (cf. chapter 13) when defining new
exception types.
try-block. The run-time support system ensures that all of the
program's code is itself surrounded by a global try block. Thus, every
exception generated by our code will always reach the boundary of at least one
try-block. A program terminates when an exception reaches
the boundary of the global try block, and when this happens destructors of
local and global objects that were alive at the point where the exception was
generated are not called. This is not a desirable situation and therefore all
exceptions should be generated within a try-block explicitly defined by
the program. Here is an example of a string exception thrown from within a
try-block:
try
{
// any code can be defined here
if (someConditionIsTrue)
throw "this is the std::string exception"s;
// any code can be defined here
}
catch: Immediately following the try-block, one or more
catch-clauses must be defined. A catch-clause consists of a
catch-header defining the type of the exception it can catch followed by a
compound statement defining what to do with the caught exception:
catch (string const &msg)
{
// statements in which the caught string object are handled
}
Multiple catch clauses may appear underneath each other, one for each
exception type that has to be caught. In general the catch clauses may
appear in any order, but there are exceptions requiring a specific order. To
avoid confusion it's best to put a catch clause for the most general
exception last. At most one exception clause will be activated. C++
does not support a Java-style finally-clause activated after
completing a catch clause.
Outer and Inner.
First, an Outer object is defined in main, and its member
Outer::fun is called. Then, in Outer::fun an Inner object is
defined. Having defined the Inner object, its member Inner::fun is
called.
That's about it. The function Outer::fun terminates calling
inner's destructor. Then the program terminates, activating
outer's destructor. Here is the basic program:
#include <iostream>
using namespace std;
class Inner
{
public:
Inner();
~Inner();
void fun();
};
Inner::Inner()
{
cout << "Inner constructor\n";
}
Inner::~Inner()
{
cout << "Inner destructor\n";
}
void Inner::fun()
{
cout << "Inner fun\n";
}
class Outer
{
public:
Outer();
~Outer();
void fun();
};
Outer::Outer()
{
cout << "Outer constructor\n";
}
Outer::~Outer()
{
cout << "Outer destructor\n";
}
void Outer::fun()
{
Inner in;
cout << "Outer fun\n";
in.fun();
}
int main()
{
Outer out;
out.fun();
}
/*
Generated output:
Outer constructor
Inner constructor
Outer fun
Inner fun
Inner destructor
Outer destructor
*/
After compiling and running, the program's output is entirely as expected:
the destructors are called in their correct order (reversing the calling
sequence of the constructors).
Now let's focus our attention on two variants in which we simulate a non-fatal
disastrous event in the Inner::fun function. This event must supposedly be
handled near main's end.
We'll consider two variants. In the first variant the event is handled by
setjmp and longjmp; in the second variant the event is handled using
C++'s exception mechanism.
jmp_buf jmpBuf used by setjmp and longjmp.
The function Inner::fun calls longjmp, simulating a disastrous
event, to be handled near main's end. In main a target location for
the long jump is defined through the function setjmp. Setjmp's zero
return indicates the initialization of the jmp_buf variable, in which case
Outer::fun is called. This situation represents the `normal flow'.
The program's return value is zero only if Outer::fun terminates
normally. The program, however, is designed in such a way that this won't
happen: Inner::fun calls longjmp. As a result the execution flow
returns to the setjmp function. In this case it does not return a zero
return value. Consequently, after calling Inner::fun from Outer::fun
main's if-statement is entered and the program terminates with return
value 1. Try to follow these steps when studying the following program
source, which is a direct modification of the basic program given in section
10.2:
#include <iostream>
#include <setjmp.h>
#include <cstdlib>
using namespace std;
jmp_buf jmpBuf;
class Inner
{
public:
Inner();
~Inner();
void fun();
};
Inner::Inner()
{
cout << "Inner constructor\n";
}
void Inner::fun()
{
cout << "Inner fun\n";
longjmp(jmpBuf, 0);
}
Inner::~Inner()
{
cout << "Inner destructor\n";
}
class Outer
{
public:
Outer();
~Outer();
void fun();
};
Outer::Outer()
{
cout << "Outer constructor\n";
}
Outer::~Outer()
{
cout << "Outer destructor\n";
}
void Outer::fun()
{
Inner in;
cout << "Outer fun\n";
in.fun();
}
int main()
{
Outer out;
if (setjmp(jmpBuf) != 0)
return 1;
out.fun();
}
/*
Generated output:
Outer constructor
Inner constructor
Outer fun
Inner fun
Outer destructor
*/
This program's output clearly shows that inner's destructor is not
called. This is a direct consequence of the non-local jump performed by
longjmp. Processing proceeds immediately from the longjmp call inside
Inner::fun to setjmp in main. There, its return value is unequal
zero, and the program terminates with return value 1. Because of the non-local
jump Inner::~Inner is never executed: upon return to main's setjmp
the existing stack is simply broken down disregarding any destructors waiting
to be called.
This example illustrates that the destructors of objects can easily be skipped
when longjmp and setjmp are used and C++ programs should therefore
avoid those functions like the plague.
setjmp and
longjmp. Here is an example using exceptions. The program is once again
derived from the basic program of section 10.2:
#include <iostream>
using namespace std;
class Inner
{
public:
Inner();
~Inner();
void fun();
};
Inner::Inner()
{
cout << "Inner constructor\n";
}
Inner::~Inner()
{
cout << "Inner destructor\n";
}
void Inner::fun()
{
cout << "Inner fun\n";
throw 1;
cout << "This statement is not executed\n";
}
class Outer
{
public:
Outer();
~Outer();
void fun();
};
Outer::Outer()
{
cout << "Outer constructor\n";
}
Outer::~Outer()
{
cout << "Outer destructor\n";
}
void Outer::fun()
{
Inner in;
cout << "Outer fun\n";
in.fun();
}
int main()
{
Outer out;
try
{
out.fun();
}
catch (int x)
{}
}
/*
Generated output:
Outer constructor
Inner constructor
Outer fun
Inner fun
Inner destructor
Outer destructor
*/
Inner::fun now throws an int exception where a longjmp was
previously used. Since in.fun is called by out.fun, the exception is
generated within the try block surrounding the out.fun call. As an
int value was thrown this value reappears in the catch clause beyond
the try block.
Now Inner::fun terminates by throwing an exception instead of calling
longjmp. The exception is caught in main, and the program
terminates. Now we see that inner's destructor is properly called. It is
interesting to note that Inner::fun's execution really terminates at the
throw statement: The cout statement, placed just beyond the throw
statement, isn't executed.
What did this example teach us?
return-statements, and
without the need to terminate the program using blunt tools like the function
exit.
setjmp and longjmp do distrupt the proper activation of
destructors their use is strongly deprecated in C++.
throw statements. The throw keyword is
followed by an expression, defining the thrown exception value. Example:
throw "Hello world"; // throws a char *
throw 18; // throws an int
throw string{ "hello" }; // throws a string
Local objects cease to exist when a function terminates. This is no different for exceptions.
Objects defined locally in functions are automatically destroyed once
exceptions thrown by these functions leave these functions. This also happens
to objects thrown as exceptions. However, just before leaving the function
context the object is copied and it is this copy that eventually reaches the
appropriate catch clause.
The following examples illustrates this process.
Object::fun defines a local Object toThrow, that is
thrown as an exception. The exception is caught
in main. But by then the object originally thrown doesn't exist anymore,
and main received a copy:
#include <iostream>
#include <string>
using namespace std;
class Object
{
string d_name;
public:
Object(string name)
:
d_name(name)
{
cout << "Constructor of " << d_name << "\n";
}
Object(Object const &other)
:
d_name(other.d_name + " (copy)")
{
cout << "Copy constructor for " << d_name << "\n";
}
~Object()
{
cout << "Destructor of " << d_name << "\n";
}
void fun()
{
Object toThrow("'local object'");
cout << "Calling fun of " << d_name << "\n";
throw toThrow;
}
void hello()
{
cout << "Hello by " << d_name << "\n";
}
};
int main()
{
Object out{ "'main object'" };
try
{
out.fun();
}
catch (Object o)
{
cout << "Caught exception\n";
o.hello();
}
}
Object's copy constructor is special in that it defines its name as
the other object's name to which the string " (copy)" is appended. This
allow us to monitor the construction and destruction of objects more closely.
Object::fun generates an exception, and throws its locally defined
object. Just before throwing the exception the program has produced the
following output:
Constructor of 'main object'
Constructor of 'local object'
Calling fun of 'main object'
When the exception is generated the next line of output is produced:
Copy constructor for 'local object' (copy)
The local object is passed to throw where it is treated as a value
argument, creating a copy of toThrow. This copy is thrown as the
exception, and the local toThrow object ceases to exist. The thrown
exception is now caught by the catch clause, defining an
Object value parameter. Since this is a value parameter yet another
copy is created. Thus, the program writes the following text:
Destructor of 'local object'
Copy constructor for 'local object' (copy) (copy)
The catch block now displays:
Caught exception
Following this o's hello member is called, showing us that we
indeed received a copy of the copy of the original toThrow object:
Hello by 'local object' (copy) (copy)
Then the program terminates and its remaining objects are now destroyed, reversing their order of creation:
Destructor of 'local object' (copy) (copy)
Destructor of 'local object' (copy)
Destructor of 'main object'
The copy created by the catch clause clearly is superfluous. It can be
avoided by defining object reference parameters in catch clauses:
`catch (Object &o)'. The program now produces the following output:
Constructor of 'main object'
Constructor of 'local object'
Calling fun of 'main object'
Copy constructor for 'local object' (copy)
Destructor of 'local object'
Caught exception
Hello by 'local object' (copy)
Destructor of 'local object' (copy)
Destructor of 'main object'
Only a single copy of toThrow was created.
It's a bad idea to throw a pointer to a locally defined object. The pointer is thrown, but the object to which the pointer refers ceases to exist once the exception is thrown. The catcher receives a wild pointer. Bad news....
Let's summarize the above findings:
if (!parse(expressionBuffer)) // parsing failed
throw "Syntax error in expression";
if (!lookup(variableName)) // variable not found
throw "Variable not defined";
if (divisionByZero()) // unable to do division
throw "Division by zero is not defined";
Where these throw statements are located is irrelevant: they may be
found deeply nested inside the program, or at a more superficial level.
Furthermore, functions may be used to generate the exception to be
thrown. An Exception object might support stream-like insertion operations
allowing us to do, e.g.,
if (!lookup(variableName))
throw Exception() << "Undefined variable '" << variableName << "';
In this situation an intermediate exception handler is called for. A thrown exception is first inspected at the middle level. If possible it is processed there. If it is not possible to process the exception at the middle level, it is passed on, unaltered, to a more superficial level, where the really tough exceptions are handled.
By placing an empty throw statement in the exception
handler's code the received exception is passed on to the next level that
might be able to process that particular type of exception. The rethrown
exception is never handled by one of its neighboring exception handlers; it
is always transferred to an exception handler at a more superficial level.
In our server-client situation a function
initialExceptionHandler(string &exception)
could be designed to handle the string exception. The received message
is inspected. If it's a simple message it's processed, otherwise the exception
is passed on to an outer level. In initialExceptionHandler's
implementation the empty throw statement is used:
void initialExceptionHandler(string &exception)
{
if (!plainMessage(exception))
throw;
handleTheMessage(exception);
}
Below (section 10.5), the empty throw statement is used
to pass on the exception received by a catch-block. Therefore, a function
like initialExceptionHandler can be used for a variety of thrown
exceptions, as long as their types match initialExceptionHandler's
parameter, which is a string.
The next example jumps slightly ahead, using some of the topics covered in chapter 14. The example may be skipped, though, without loss of continuity.
A basic exception handling class can be constructed from which specific
exception types are derived. Suppose we have a class Exception, having a
member function ExceptionType Exception::severity. This member function
tells us (little wonder!) the severity of a thrown exception. It might be
Info, Notice, Warning, Error or Fatal. The information contained in
the exception depends on its severity and is processed by a function
handle. In addition, all exceptions support a member function like
textMsg, returning textual information about the exception in a
string.
By defining a polymorphic function handle it can be made to behave
differently, depending on the nature of a thrown exception, when called
from a basic Exception pointer or reference.
In this case, a program may throw any of these five exception types. Assuming
that the classes Message and Warning were derived from the class
Exception, then the handle function matching the exception type will
automatically be called by the following exception catcher:
//
catch(Exception &ex)
{
cout << e.textMsg() << '\n';
if
(
ex.severity() != ExceptionType::Warning
&&
ex.severity() != ExceptionType::Message
)
throw; // Pass on other types of Exceptions
ex.handle(); // Process a message or a warning
}
Now anywhere in the try block preceding the exception handler
Exception objects or objects of one of its derived classes may be
thrown. All those exceptions will be caught by the above handler. E.g.,
throw Info{};
throw Warning{};
throw Notice{};
throw Error{};
throw Fatal{};
try-block surrounds throw statements. Remember that a program is
always surrounded by a global try block, so throw statements may
appear anywhere in your code. More often, though, throw statements are
used in function bodies and such functions may be called from within try
blocks.
A try block is defined by the keyword try followed by a compound
statement. This block, in turn, must be followed by at least one
catch handler:
try
{
// any statements here
}
catch(...) // at least one catch clause here
{}
Try-blocks are commonly nested, creating exception levels. For
example, main's code is surrounded by a try-block, forming an outer
level handling exceptions. Within main's try-block functions are
called which may also contain try-blocks, forming the next exception
level. As we have seen (section 10.3.1), exceptions thrown in
inner level try-blocks may or may not be processed at that level. By
placing an empty throw statement in an exception handler, the
thrown exception is passed on to the next (outer) level.
catch clause consists of the keyword catch followed by a parameter
list defining one parameter specifying type and (parameter) name of the
exception caught by that particular catch handler. This name may then be
used as a variable in the compound statement following the catch clause.
Example:
catch (string &message)
{
// code to handle the message
}
Primitive types and objects may be thrown as exceptions. It's a bad idea to throw a pointer or reference to a local object, but a pointer to a dynamically allocated object may be thrown if the exception handler deletes the allocated memory to prevent a memory leak. Nevertheless, throwing such a pointer is dangerous as the exception handler won't be able to distinguish dynamically allocated memory from non-dynamically allocated memory, as illustrated by the next example:
try
{
static int x;
int *xp = &x;
if (condition1)
throw xp;
xp = new int(0);
if (condition2)
throw xp;
}
catch (int *ptr)
{
// delete ptr or not?
}
Close attention should be paid to the nature of the parameter of the
exception handler, to make sure that when pointers to dynamically allocated
memory are thrown the memory is returned once the handler has processed
the pointer. In general pointers should not be thrown as exceptions. If
dynamically allocated memory must be passed to an exception handler then the
pointer should be wrapped in a smart pointer, like unique_ptr or
shared_ptr (cf. sections 18.3 and 18.4).
Multiple catch handlers may follow a try block, each handler
defining its own exception type. The order
of the exception handlers is important. When an exception is thrown, the first
exception handler matching the type of the thrown exception is used and
remaining exception handlers are ignored. Eventually at most one exception
handler following a try-block is activated. Normally this is of no
concern as each exception has its own unique type.
Example: if exception handlers are defined for char *s and void *s
then NTBSs are caught by the former handler. Note that a char
* can also be considered a void *, but the exception type matching
procedure is smart enough to use the char * handler with the thrown
NTBS. Handlers should be designed very type specific to catch the
correspondingly typed exception. For example, int-exceptions are not
caught by double-catchers, char-exceptions are not caught by
int-catchers. Here is a little example illustrating that the order of the
catchers is not important for types not having any hierarchal relationship to
each other (i.e., int is not derived from double; string is not
derived from an NTBS):
#include <iostream>
using namespace std;
int main()
{
while (true)
{
try
{
string s;
cout << "Enter a,c,i,s for ascii-z, char, int, string "
"exception\n";
getline(cin, s);
switch (s[0])
{
case 'a':
throw "ascii-z";
case 'c':
throw 'c';
case 'i':
throw 12;
case 's':
throw string{};
}
}
catch (string const &)
{
cout << "string caught\n";
}
catch (char const *)
{
cout << "ASCII-Z string caught\n";
}
catch (double)
{
cout << "isn't caught at all\n";
}
catch (int)
{
cout << "int caught\n";
}
catch (char)
{
cout << "char caught\n";
}
}
}
Rather than defining specific exception handlers a specific class can be
designed whose objects contain information about the exception. Such an
approach was mentioned earlier, in section 10.3.1. Using this
approach, there's only one handler required, since we know we don't throw
other types of exceptions:
try
{
// code throws only Exception objects
}
catch (Exception &ex)
{
ex.handle();
}
When the code of an exception handler has been processed, execution continues
beyond the last exception handler directly following the matching
try-block (assuming the handler doesn't itself use flow control statements
(like return or throw) to break the default flow of execution). The
following cases can be distinguished:
try-block no exception
handler is activated, and execution continues from the last statement in
the try-block to the first statement beyond the last catch-block.
try-block but neither
the current level nor another level contains an appropriate exception handler,
the program's default exception handler is called, aborting the program.
try-block and an appropriate
exception handler is available, then the code of that exception handler is
executed. Following that, the program's execution continues at the first
statement beyond the last catch-block.
try block following an executed
throw-statement are ignored. However, objects that were successfully
constructed within the try block before executing the throw statement
are destroyed before any exception handler's code is executed.
try block.
An intermediate type of exception handling may be implemented using the default exception handler, which must be (due to the hierarchal nature of exception catchers, discussed in section 10.5) placed beyond all other, more specific exception handlers.
This default exception handler cannot determine the actual type of the thrown
exception and cannot determine the exception's value but it may execute some
statements, and thus do some default processing. Moreover, the caught
exception is not lost, and the default exception handler may use the empty
throw statement (see section 10.3.1) to pass the exception on to
an outer level, where it's actually processed. Here is an example showing
this use of a default exception handler:
#include <iostream>
using namespace std;
int main()
{
try
{
try
{
throw 12.25; // no specific handler for doubles
}
catch (int value)
{
cout << "Inner level: caught int\n";
}
catch (...)
{
cout << "Inner level: generic handling of exceptions\n";
throw;
}
}
catch(double d)
{
cout << "Outer level may use the thrown double: " << d << '\n';
}
}
/*
Generated output:
Inner level: generic handling of exceptions
Outer level may use the thrown double: 12.25
*/
The program's output illustrates that an empty throw statement in a
default exception handler throws the received exception to the next (outer)
level of exception catchers, keeping type and value of the thrown exception.
Thus, basic or generic exception handling can be accomplished at an inner
level, while specific handling, based on the type of the thrown expression,
can be provided at an outer level. Additionally, particularly in
multi-threaded programs (cf. chapter 20), thrown exceptions can be
transferred between threads after converting std::exception objects to
std::exception_ptr objects. This proceduce can even be used from inside
the default catcher. Refer to section 20.12.1 for further coverage of the
class std::exception_ptr.
swap and destructors may not throw exceptions.
Functions that may not throw exceptions can be declared and defined by
specifying the noexcept keyword (see section 10.9 for examples
of function declarations specifying noexcept).
When using noecept there's a slight run-time overhead penalty because the
function needs an over-all try-catch block catching any eception that
might be thrown by its (called) code. When an exception is caught (violating
the noexcept specification) then the catch clause calls
std::terminate, ending the program.
In addition to using a plain noexcept, it can also be given an argument
that is evaluated compile-time (e.g., void fun() noexcept(sizeof(int) ==
4)): if the evaluation returns true then the noexcept requirement is
used; if the evaluation returns false, then the noexcept requirement
is ignored. Examples of this advanced use of noexcept are provided in
section 23.8.
ios::exceptions member function. This function has two overloaded
versions:
ios::iostate exceptions():void exceptions(ios::iostate state)
this member causes the stream to throw an exception
when state state is observed.
ios::failure, derived from
ios::exception. A std::string const &message may be specified when
defining a failure object. Its message may then be retrieved using its
virtual char const *what() const member.
Exceptions should be used in exceptional circumstances. Therefore, we
think it is questionable to have stream objects throw exceptions for fairly
normal situations like EOF. Using exceptions to handle input errors
might be defensible (e.g., in situations where input errors should not occur
and imply a corrupted file) but often aborting the program with an appropriate
error message would probably be the more appropriate action. As an example
consider the following interactive program using exceptions to catch incorrect
input:
#include <iostream>
#include <climits>
using namespace::std;
int main()
{
cin.exceptions(ios::failbit); // throw exception on fail
while (true)
{
try
{
cout << "enter a number: ";
int value;
cin >> value;
cout << "you entered " << value << '\n';
}
catch (ios::failure const &problem)
{
cout << problem.what() << '\n';
cin.clear();
cin.ignore(INT_MAX, '\n'); // ignore the faulty line
}
}
}
By default, exceptions raised from within ostream objects are caught by
these objects, which set their ios::badbit as a result. See also the
paragraph on this issue in section 14.8.
<stdexcept> header file must be included.
All of these standard exceptions
are class types by themselves, but also offer
all facilities of the std::exception class and objects
of the standard exception classes may also be considered objects of the
std::exception class.
The std::exception class offers the member
char const *what() const;
describing in a short textual message the nature of the exception.
C++ defines the following standard exception classes:
std::bad_alloc (this requires the <new> header file):
thrown when operator new fails;
std::bad_array_new_length (this requires the
<new> header file): thrown when an illegal array size is requested
when using new Type[...]. Illegal sizes are negative values,
values that exceed an implementation defined maximum, the number of
initializer clauses exceeds the specified number of array elements
(e.g., new int[2]{ 1, 2, 3 });
std::bad_cast (this requires the <typeinfo> header
file): thrown in the context of polymorphism
(see section 14.6.1);
std::bad_exception (this requires the
<exception> header file): thrown when a function tries to
generate another type of exception than declared in its
function throw list;
std::bad_typeid (this requires the <typeinfo> header
file): also thrown in the context of
polymorphism (see section 14.6.2);
All additional exception classes were derived from std::exception. The
constructors of all these additional classes accept std::string const &
arguments summarizing the reason for the exception (retrieved by the
exception::what member). The additionally defined exception classes are:
std::domain_error: a (mathematical) domain error is
detected;
std::invalid_argument: the argument of a function
has an invalid value;
std::length_error: thrown when an object would have
exceeded its maximum permitted length;
std::logic_error: a logic error should be thrown when a
problem is detected in the internal logic of the program. Example: a function
like C's printf is called with more arguments than there are format
specifiers in its format string;
std::out_of_range: thrown when an argument exceeds its
permitted range. Example: thrown by at members when their arguments exceed
the range of admissible index values;
std::overflow_error: an overflow error should be
thrown when an arithmetic overflow is detected. Example: dividing a
value by a very small value;
std::range_error: a range error should be thrown when
an internal computation results in a value exceeding a permissible range;
std::runtime_error: a runtime error should be thrown
when a problem is encountered that can only be detected while the program is
being executed. Example: a non-integral is entered when the program's input
expects an integral value.
std::underflow_error: an underflow error should be
thrown when an arithmetic underflow is detected. Example: dividing a very
small value by a very large value.
std::tx_exception<Type>: derived from
std::runtime_error. This exception can be thrown from an atomic_cancel
compound statement (cf. section 20.14) to undo statements executed so
far.
Current practice in the C++ community is to throw exceptions only in
exceptional situations. In that respect C++'s philosophy about using
exceptions differs markedly from the way exceptions are used in, e.g., Java,
where exceptions are often encountered in situations C++ doesn't consider
exceptional. Another common practice is to follow a `conceptual' style when
designing software. A nice characteristic of exceptions is that exceptions can
be thrown at a point where your source shows what's happening: throwing an
std::out_of_range exception is nice for the software maintainer, as
the reason for the exception is immediately recognized.
At the catch-clause the semantical context usually isn't very relevant anymore
and by catching a std::exception and showing its what() content the
program's user is informed about what happened.
But throwing values of other types can also be useful. What about a situation
where you want to throw an exception and catch it at some shallow level? In
between there may be various levels of software provided by external software
libraries over which the software engineer has no control. At those levels
exceptions (std::exceptions) could be generated too, and those exceptions
might also be caught by the library's code. When throwing a standard exception
type it may be hard to convince yourself that that exception isn't caught by
the externally provided software. Assuming that no catch-alls are used (i.e.,
catch (...)) then throwing an exception from the std::exception
family might not be a very good idea. In such cases throwing a value from a
simple, maybe empty, enum works fine:
enum HorribleEvent
{};
... at some deep level:
throw HorribleEvent{};
... at some shallow level:
catch (HorribleEvent hs)
{
...
}
Other examples can easily be found: design a class holding a message and an error (exit) code: where necessary throw an object of that class, catch it in the catch clause of main's try block and you can be sure that all objects defined at intermediate levels are neatly destroyed, and at the end you show the error message and return the exit code embedded in your non-exception object.
So, the advice is to use std::exception types when available, and
clearly do the required job. But if an exception is used to simply bail out
of an unpleasant situation, or if there's a chance that externally provided
code might catch std:exceptions then consider throwing objects or values
of other types.
std::system_error is derived from
std::runtime_error, which in turn is derived from std::exception
Before using the class system_error or related classes the
<system_error> header file must be included.
System_error exceptions can be thrown when errors occur having
associated (system) error values. Such errors are typically associated
with low-level (like operating system) functions, but other types of errors
(e.g., bad user input, non-existing requests) can also be handled.
In addition to error codes (cf. section 4.3.2) and error categories (covered below) error conditions are distinguished. Error conditions specify platform independent types of errors like syntax errors or non-existing requests.
When constructing system_error objects error codes and error categories
may be specified. First we'll look at the classes error_condition and
error_category, then system_error itself is covered in more detail.
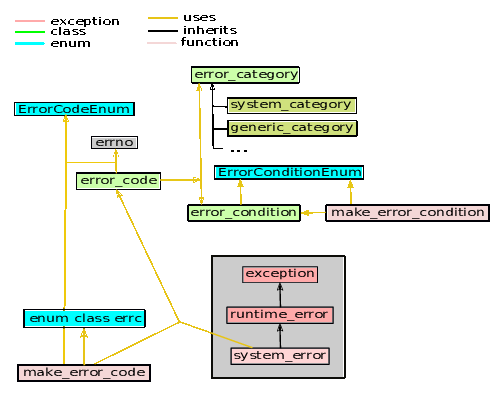
Figure 9 illustrates how the various components interact.
As shown in figure 9 the class error_category uses the class
error_condition and the class error_condition uses the class
error_category. As a consequence of this circular dependency between these
two classes these classes should be approached as one single class:
when covering error_category the class error_condition should be known
and vice versa. This circular dependency among these classes is unfortunate
and an example of bad class design.
As system_error is eventually derived from exception it offers the
standard what member. It also contains an error_code.
In POSIX systems the errno variable is associated with many, often rather
cryptic, symbols. The predefined enum class errc attempts to provide
intuitively more appealing symbols. Since its symbols are defined in a
strongly typed enumeration, they cannot directly be used when defining a
matching error_code. Instead, a make_error_code function converts
enum class errc values and values of newly defined
error code enumerations (called ErrorCodeEnum below) to error_code
objects.
The enum class errc defined in the std namespace defines symbols whose
values are equal to the traditional error code values used by C but
describe the errors in a less cryptic way. E.g.,
enum class errc
{
address_family_not_supported, // EAFNOSUPPORT
address_in_use, // EADDRINUSE
address_not_available, // EADDRNOTAVAIL
already_connected, // EISCONN
argument_list_too_long, // E2BIG
argument_out_of_domain, // EDOM
bad_address, // EFAULT
...
};
Values of ErrorCodeEnums can be passed to matching make_error_code
functions. Defining your own ErrorCodeEnum enumeration is covered in
section 23.7.
Now that the general outline has been presented, it's time to have a closer look at the various components shown in figure 9.
std::error_category identify sources of sets of error
codes. New error categories for new error code enumerations can also be
defined (cf. section 23.7).
Error categories are designed as singletons: only one object of each class
can exist. Because of this error_categories are equal when the addresses
of error_category objects are equal. Error category objects are returned
by functions (see below) or by static instance() members of error category
classes.
Error category classes define several members. Most are declared virtual (cf. chapter 14), meaning that those members may be redefined in error category classes we ourselves design:
virtual error_condition
default_error_condition(int ev) const noexcept:error_condition object (cf. section 10.9.2)
initialized with error value ev and the current
(i.e., *this) error_category;
virtual bool equivalent(error_code const &code, int condition) const
noexcept:true if the equivalence between
the error condition that is associated with the error_code object
and the error_condition_enum value that is specified (as an
int value) as the function's second argument could be
establisted;
virtual bool equivalent(int ev, error_condition const &condition)
const noexcept:true if the equivalence of an error_condition object
that is constructed from the ErrorConditionEnum value that is
associated with the ErrorCategoryEnum value that was passed (as
int) to the function and the error_condition object that was
passed to the function as its second argument could be established;
virtual string message(int ev) const:ev, which should be a (cast to int) value of the category's
error condition enumeration;
virtual char const *name() const noexcept:generic);
bool operator<(error_category const &rhs) const noexcept:less<const error_category*>()(this, &rhs).
The functions returning predefined error categories are:
error_category const &generic_category() noexcept:error_category object.
The returned object's name member returns a pointer to the string
"generic";
error_category const &system_category() noexcept:error_category
object: it is used for errors reported by the operating system. The
object's name member returns a pointer to the string
"system";
error_category const &iostream_category() noexcept:error_category
object: it is used for errors reported by stream objects. The
object's name member returns a pointer to the string
"iostream";
error_category const &future_category() noexcept:error_category object: it is
used for errors reported by `future' objects (cf. section
20.8). The object's name member returns a pointer to the
string "future";
Error_condition objects contain information about
`higher level' types of errors. They are supposed to be platform independent
like syntax errors or non-existing requests.
Error condition objects are returned by the member default_error_condition
of the classes error_code and error_category, and they are returned by
the function std::error_condition
make_error_condition(ErrorConditionEnum ec). The type name
ErrorConditionEnum is a formal name for an enum class that enumerates
the `higher level' error types. The error_condition objects returned by
make_error_condition are initialized with ec and the
error_category that uses the ErrorConditionEnum. Defining your own
ErrorConditionEnum is covered in section 23.7.
Constructors:
error_condition() noexcept:system_category error category;
error_condition(int ec, error_category const &cat) noexcept:ec and error category
cat. It is the responsibility of the caller to ensure that ec
represents a (cast to int) value of cat's error condition
enumeration;
error_condition(ErrorConditionEnum value) noexcept:template <class ErrorConditionEnum>. It initializes the
object with the return value of
make_error_condition(value);
Members:
ErrorConditionEnum are available;
void assign(int val, error_category const &cat):
error_category const &category() const noexcept:
void clear() noexcept:generic_category;
string message() const:category().message(value());
explicit operator bool() const noexcept:true if value() returns a non-zero value (so its
semantic meaning is `the object represents an error');
int value() const noexcept:
Two error_condition objects can be compared for (in)equality, and can be
ordered using operator<. Ordering is pointless if the two objects refer to
different error categories. If the categories of two objects are different
they are considered different.
System_error objects can be constructed from error_codes or from
error values (ints) and matching error category objects, optionally
followed by a standard textual description of the nature of the encountered
error.
Here is the class's public interface:
class system_error: public runtime_error
{
public:
system_error(error_code ec);
system_error(error_code ec, string const &what_arg);
system_error(error_code ec, char const *what_arg);
system_error(int ev, error_category const &ecat);
system_error(int ev, error_category const &ecat,
char const *what_arg);
system_error(int ev, error_category const &ecat,
string const &what_arg);
error_code const &code() const noexcept;
char const *what() const noexcept;
}
The ev values often are the values of the errno variable as set
upon failure by system level functions like chmod(2).
Note that the first three constructors shown in the interface receive an
error_code object as their first arguments. As one of the error_code
constructors also expects an int and and error_category argument,
the second set of three constructors could also be used instead of the first
set of three constructors. E.g.,
system_error(errno, system_category(), "context of the error");
// identical to:
system_error(error_code(errno, system_category()),
"context of the error");
The second set of three constructors are primarily used when an existing
function already returns an error_code. E.g.,
system_error(make_error_code(errc::bad_address),
"context of the error");
// or maybe:
system_error(make_error_code(static_cast<errc>(errno)),
"context of the error");
In addition to the standard what member, the system_error class also
offers a member code returning a const reference to the exception's error
code.
The NTBS returned by system_error's what member may be formatted by a
system_error object:
what_arg + ": " + code().message()
Note that, although system_error was derived from runtime_error,
you'll lose the code member when catching a std::exception object. Of
course, downcasting is possible, but that's a stopgap. Therefore, if a
system_error is thrown, a matching catch(system_error const &) clause
must be provided to retrieve the value returned by the code member. This,
and the rather complex organization of the classes that are involved when
using system_error result in a very complex, and hard to generalize
exception handling. In essence, what you obtain at the cost of high
complexity is a facility for categorizing int or enum error
values. Additional coverage of the involved complexities is provided in
chapter 23, in particular section 23.7
(for a flexible alternative, see the class
FBB::Exception in the author's
Bobcat library).
Since exceptions may be generated from within all C++ functions, exceptions may be generated in many situations. Not all of these situations are immediately and intuitively recognized as situations where exceptions can be thrown. Consider the following function and ask yourself at which points exceptions may be thrown:
void fun()
{
X x;
cout << x;
X *xp = new X{ x };
cout << (x + *xp);
delete xp;
}
If it can be assumed that cout as used above does not throw an
exception there are at least 13 opportunities for exceptions to be thrown:
X x: the default constructor could throw an exception (#1)
cout << x: the overloaded insertion operator could throw an
exception (#2), but its rhs argument might not be an X but, e.g., an
int, and so X::operator int() const could be called which offers yet
another opportunity for an exception (#3).
*xp = new X{ x }: the copy constructor may throw an exception
(#4) and operator new (#5a) too. But did you realize that this latter
exception might not be thrown from ::new, but from, e.g., X's own
overload of operator new? (#5b)
cout << (x + *xp): we might be seduced into thinking that two
X objects are added. But it doesn't have to be that way. A separate class
Y might exist and X may have a conversion operator operator Y() const,
and operator+(Y const &lhs, X const &rhs), operator+(X const &lhs, Y const
&rhs), and operator+(X const &lhs, X const &rhs) might all exist. So, if
the conversion operator exists, then depending on the kind of overload of
operator+ that is defined either the addition's left-hand side operand
(#6), right-hand side operand (#7), or operator+ itself (#8) may throw an
exception. The resulting value may again be of any type and so the overloaded
cout << return-type-of-operator+ operator may throw an exception
(#9). Since operator+ returns a temporary object it is destroyed shortly
after its use. X's destructor could throw an exception (#10).
delete xp: whenever operator new is overloaded operator
delete should be overloaded as well and may throw an exception (#11). And of
course, X's destructor might again throw an exception (#12).
}: when the function terminates the local x object is
destroyed: again an exception could be thrown (#13).
How can we expect to create working programs when exceptions might be thrown in so many situations?
Exceptions may be generated in a great many situations, but serious problems are prevented when we're able to provide at least one of the following exception guarantees:
void allocator(X **xDest, Y **yDest)
{
X *xp = 0; // non-throwing preamble
Y *yp = 0;
try // this part might throw
{
xp = new X[nX]; // alternatively: allocate one object
yp = new Y[nY];
}
catch(...)
{
delete xp;
throw;
}
delete[] *xDest; // non-throwing postamble
*xDest = xp;
delete[] *yDest;
*yDest = yp;
}
In the pre-try code the pointers to receive the addresses returned by the
operator new calls are initialized to 0. Since the catch handler must be
able to return allocated memory they must be available outside of the try
block. If the allocation succeeds the memory pointed to by the destination
pointers is returned and then the pointers are given new values.
Allocation and or initialization might fail. If allocation fails new
throws a std::bad_alloc exception and the catch handler
simply deletes 0-pointers which is OK.
If allocation succeeds but the construction of (some) of the objects fails by throwing an exception then the following is guaranteed to happen:
Consequently, there is no memory leak when new fails. Inside the above
try block new X may fail: this does not affect the 0-pointers
and so the catch handler merely deletes 0 pointers. When new Y fails
xp points to allocated memory and so it must be returned. This happens
inside the catch handler. The final pointer (here: yp) will only be
unequal zero when new Y properly completes, so there's no need for the
catch handler to return the memory pointed at by yp.
Class &operator=(Class const &other)
{
Class tmp(other);
swap(tmp);
return *this;
}
The copy construction might throw an exception, but this keeps the current
object's state intact. If the copy construction succeeds swap swaps the
current object's content with tmp's content and returns a reference to
the current object. For this to succeed it must be guaranteed that swap
won't throw an exception. Returning a reference (or a value of a primitive
data type) is also guaranteed not to throw exceptions. The canonical form of
the overloaded assignment operator therefore meets the requirements of the
strong guarantee.
Some rules of thumb were formulated that relate to the strong guarantee (cf. Sutter, H., Exceptional C++, Addison-Wesley, 2000). E.g.,
The canonical assignment operator is a good example of the first rule of
thumb. Another example is found in classes storing objects. Consider a class
PersonDb storing multiple Person objects. Such a class might offer a
member void add(Person const &next). A plain implementation of this
function (merely intended to show the application of the first rule of thumb,
but otherwise completely disregarding efficiency considerations) might be:
Person *PersonDb::newAppend(Person const &next)
{
Person *tmp = 0;
try
{
tmp = new Person[d_size + 1];
for (size_t idx = 0; idx < d_size; ++idx)
tmp[idx] = d_data[idx];
tmp[d_size] = next;
return tmp;
}
catch (...)
{
delete[] tmp;
throw;
}
}
void PersonDb::add(Person const &next)
{
Person *tmp = newAppend(next);
delete[] d_data;
d_data = tmp;
++d_size;
}
The (private) newAppend member's task is to create a copy of the
currently allocated Person objects, including the data of the next
Person object. Its catch handler catches any exception that might be
thrown during the allocation or copy process and returns all memory
allocated so far, rethrowing the exception at the end. The function is
exception neutral as it propagates all its exceptions to its caller. The
function also doesn't modify the PersonDb object's data, so it meets the
strong exception guarantee. Returning from newAppend the member add
may now modify its data. Its existing data are returned and its d_data
pointer is made to point to the newly created array of Person
objects. Finally its d_size is incremented. As these three steps don't
throw exceptions add too meets the strong guarantee.
The second rule of thumb (member functions modifying their object's data
should not return original (contained) objects by value) may be illustrated
using a member PersonDb::erase(size_t idx). Here is an implementation
attempting to return the original d_data[idx] object:
Person PersonData::erase(size_t idx)
{
if (idx >= d_size)
throw "Array bounds exceeded"s;
Person ret(d_data[idx]);
Person *tmp = copyAllBut(idx);
delete[] d_data;
d_data = tmp;
--d_size;
return ret;
}
Although copy elision usually prevents the use of the copy constructor
when returning ret, this is not guaranteed to happen. Furthermore, a copy
constructor may throw an exception. If that happens the function has
irrevocably mutated the PersonDb's data, thus losing the strong guarantee.
Rather than returning d_data[idx] by value it might be assigned to an
external Person object before mutating PersonDb's data:
void PersonData::erase(Person *dest, size_t idx)
{
if (idx >= d_size)
throw "Array bounds exceeded"s;
*dest = d_data[idx];
Person *tmp = copyAllBut(idx);
delete[] d_data;
d_data = tmp;
--d_size;
}
This modification works, but changes the original assignment of creating a
member returning the original object. However, both functions suffer from a
task overload as they modify PersonDb's data and also return an original
object. In situations like these the one-function-one-responsibility
rule of thumb should be kept in mind: a function should have a single, well
defined responsibility.
The preferred approach is to retrieve PersonDb's objects using a member
like Person const &at(size_t idx) const and to erase an object using a
member like void PersonData::erase(size_t idx).
swap function. Consider once again the canonical
overloaded assignment operator:
Class &operator=(Class const &other)
{
Class tmp(other);
swap(tmp);
return *this;
}
If swap were allowed to throw exceptions then it would most likely
leave the current object in a partially swapped state. As a result the current
object's state would most likely have been changed. As tmp has been
destroyed by the time a catch handler receives the thrown exception it becomes
very difficult (as in: impossible) to retrieve the object's original
state. Losing the strong guarantee as a consequence.
The swap function must therefore offer the nothrow guarantee. It must
have been designed as if using the following prototype (see also section
23.8):
void Class::swap(Class &other) noexcept;
Likewise, operator delete and operator delete[] offer the nothrow
guarantee, and according to the C++ standard destructors may themselves
not throw exceptions (if they do their behavior is formally undefined, see
also section 10.12 below).
Since the C programming language does not define the exception concept
functions from the standard C library offer the nothrow guarantee
by implication. This allowed us to define the generic swap function in
section 9.6 using memcpy.
Operations on primitive types offer the nothrow guarantee. Pointers may be reassigned, references may be returned etc. etc. without having to worry about exceptions that might be thrown.
try block does not solve the problem. The exception by
then has left the constructor and the object we intended to construct isn't
visible anymore.
Using a nested try block is illustrated in the next example, where
main defines an object of class PersonDb. Assuming that
PersonDb's constructor throws an exception, there is no way we can access
the resources that might have been allocated by PersonDb's constructor
from the catch handler as the pdb object is out of scope:
int main(int argc, char **argv)
{
try
{
PersonDb pdb{ argc, argv }; // may throw exceptions
... // main()'s other code
}
catch(...) // and/or other handlers
{
... // pdb is inaccessible from here
}
}
Although all objects and variables defined inside a try block are
inaccessible from its associated catch handlers, object data members were
available before starting the try block and so they may be accessed from a
catch handler. In the following example the catch handler in
PersonDb's constructor is able to access its d_data member:
PersonDb::PersonDb(int argc, char **argv)
:
d_data(0),
d_size(0)
{
try
{
initialize(argc, argv);
}
catch(...)
{
// d_data, d_size: accessible
}
}
Unfortunately, this does not help us much. The initialize member is
unable to reassign d_data and d_size if PersonDb const pdb
was defined; the initialize member should at least offer the basic
exception guarantee and return any resources it has acquired before
terminating due to a thrown exception; and although d_data and d_size
offer the nothrow guarantee as they are of primitive data types a class type
data member might throw an exception, possibly resulting in violation of the
basic guarantee.
In the next implementation of PersonDb assume that constructor
receives a pointer to an already allocated block of Person objects. The
PersonDb object takes ownership of the allocated memory and it is
therefore responsible for the allocated memory's eventual destruction.
Moreover, d_data and d_size are also used by a composed object
PersonDbSupport, having a constructor expecting a Person const * and
size_t argument. Our next implementation may then look something like
this:
PersonDb::PersonDb(Person *pData, size_t size)
:
d_data(pData),
d_size(size),
d_support(d_data, d_size)
{
// no further actions
}
This setup allows us to define a PersonDb const &pdb. Unfortunately,
PersonDb cannot offer the basic guarantee. If PersonDbSupport's
constructor throws an exception it isn't caught although d_data already
points to allocated memory.
The function try block offers a solution for this problem. A function
try block consists of a try block and its associated handlers. The
function try block starts immediately after the function header, and
its block defines the function body. With constructors base class and data
member initializers may be placed between the try keyword and the opening
curly brace. Here is our final implementation of PersonDb, now offering
the basic guarantee:
PersonDb::PersonDb(Person *pData, size_t size)
try
:
d_data(pData),
d_size(size),
d_support(d_data, d_size)
{}
catch (...)
{
delete[] d_data;
}
Let's have a look at a stripped-down example. A constructor defines a
function try block. The exception thrown by the Throw object is initially
caught by the object itself. Then it is rethrown. The surrounding
Composer's constructor also defines a function try block, Throw's
rethrown exception is properly caught by Composer's exception handler,
even though the exception was generated from within its member initializer
list:
#include <iostream>
class Throw
{
public:
Throw(int value)
try
{
throw value;
}
catch(...)
{
std::cout << "Throw's exception handled locally by Throw()\n";
throw;
}
};
class Composer
{
Throw d_t;
public:
Composer()
try // NOTE: try precedes initializer list
:
d_t(5)
{}
catch(...)
{
std::cout << "Composer() caught exception as well\n";
}
};
int main()
{
Composer c;
}
When running this example, we're in for a nasty surprise: the program runs and then breaks with an abort exception. Here is the output it produces, the last two lines being added by the system's final catch-all handler, catching all remaining uncaught exceptions:
Throw's exception handled locally by Throw()
Composer() caught exception as well
terminate called after throwing an instance of 'int'
Abort
The reason for this is documented in the C++ standard: at the end of a catch-handler belonging to a constructor or destructor function try block, the original exception is automatically rethrown.
The exception is not rethrown if the handler itself throws another exception, offering the constructor or destructor a way to replace a thrown exception by another one. The exception is only rethrown if it reaches the end of the catch handler of a constructor or destructor function try block. Exceptions caught by nested catch handlers are not automatically rethrown.
As only constructors and destructors rethrow exceptions caught by their
function try block catch handlers the run-time error encountered in the above
example may simply be repaired by providing main with its own function try
block:
int main()
try
{
Composer c;
}
catch (...)
{}
Now the program runs as planned, producing the following output:
Throw's exception handled locally by Throw()
Composer() caught exception as well
A final note: if a function defining a function try block also declares an exception throw list then only the types of rethrown exceptions must match the types mentioned in the throw list.
The following example illustrates this situation in its prototypical
form. The constructor of the class Incomplete first displays a message
and then throws an exception. Its destructor also displays a message:
class Incomplete
{
public:
Incomplete()
{
cerr << "Allocated some memory\n";
throw 0;
}
~Incomplete()
{
cerr << "Destroying the allocated memory\n";
}
};
Next, main() creates an Incomplete object inside a try
block. Any exception that may be generated is subsequently caught:
int main()
{
try
{
cerr << "Creating `Incomplete' object\n";
Incomplete{};
cerr << "Object constructed\n";
}
catch(...)
{
cerr << "Caught exception\n";
}
}
When this program is run, it produces the following output:
Creating `Incomplete' object
Allocated some memory
Caught exception
Thus, if Incomplete's constructor would actually have allocated some
memory, the program would suffer from a memory leak. To prevent this from
happening, the following counter measures are available:
try block, allowing the exception to be caught
by the constructor itself. This approach is defensible when the constructor
is able to repair the cause of the exception and to complete its construction
as a valid object.
try block within the constructor's
body won't be able to catch the thrown exception. This always results in
the exception leaving the constructor and the object is not considered to have
been properly constructed. A try block may include the member
initializers, and the try block's compound statement becomes the
constructor's body as in the following example:
class Incomplete2
{
Composed d_composed;
public:
Incomplete2()
try
:
d_composed(/* arguments */)
{
// body
}
catch (...)
{}
};
An exception thrown by either the member initializers or the body results in the execution never reaching the body's closing curly brace. Instead the catch clause is reached. Since the constructor's body isn't properly completed the object is not considered properly constructed and eventually the object's destructor won't be called.
try block behaves
slightly different than a catch clause of an ordinary function try
block. An exception reaching a constructor's function try block may be
transformed into another exception (which is thrown from the catch clause) but
if no exception is explicitly thrown from the catch clause the exception
originally reaching the catch clause is always rethrown. Consequently, there's
no way to confine an exception thrown from a base class constructor or from a
member initializer to the constructor: such an exception always propagates
to a more shallow block and in that case the object's construction is always
considered incomplete.
Consequently, if incompletely constructed objects throw exceptions then the constructor's catch clause is responsible for preventing memory (generally: resource) leaks. There are several ways to realize this:
shared_ptr
objects are, after all, objects.
class Incomplete2
{
Composed d_composed;
char *d_cp; // plain pointers
int *d_ip;
public:
Incomplete2(size_t nChars, size_t nInts)
try
:
d_composed(/* arguments */), // might throw
d_cp(0),
d_ip(0)
{
preamble(); // might throw
d_cp = new char[nChars]; // might throw
d_ip = new int[nChars]; // might throw
postamble(); // might throw
}
catch (...)
{
delete[] d_cp; // clean up
delete[] d_ip;
}
};
On the other hand, since C++ supports constructor delegation an object may have been completely constructed according to the C++ run-time system, but yet its constructor may have thrown an exception. This happens if a delegated constructor successfully completes (after which the object is considered `completely constructed'), but the constructor itself throws an exception, as illustrated by the next example:
class Delegate
{
public:
Delegate()
:
Delegate(0)
{
throw 12; // throws but completely constructed
}
Delegate(int x) // completes OK
{}
};
int main()
try
{
Delegate del; // throws
} // del's destructor is called here
catch (...)
{}
In this example it is the responsibility of Delegate's designer to
ensure that the throwing default constructor does not invalidate the actions
performed by Delegate's destructor. E.g., if the delegated constructor
allocates memory to be deleted by the destructor, then the default constructor
should either leave the memory as-is, or it can delete the memory and set the
corresponding pointer to zero thereafter. In any case, it is Delegate's
responsibility to ensure that the object remains in a valid state, even though
it throws an exception.
According to the C++ standard exceptions thrown by destructors may not
leave their bodies. Providing a destructor with a function try block is
therefore a violation of the standard: exceptions caught by a function try
block's catch clause have already left the destructor's body. If --in
violation of the standard-- the destructor is provided with a function
try block and an exception is caught by the try block then that
exception is rethrown, similar to what happens in catch clauses of
constructor functions' try blocks.
The consequences of an exception leaving the destructor's body is not defined, and may result in unexpected behavior. Consider the following example:
Assume a carpenter builds a cupboard having a single drawer. The cupboard is finished, and a customer, buying the cupboard, finds that the cupboard can be used as expected. Satisfied with the cupboard, the customer asks the carpenter to build another cupboard, this time having two drawers. When the second cupboard is finished, the customer takes it home and is utterly amazed when the second cupboard completely collapses immediately after it is used for the first time.
Weird story? Then consider the following program:
int main()
{
try
{
cerr << "Creating Cupboard1\n";
Cupboard1{};
cerr << "Beyond Cupboard1 object\n";
}
catch (...)
{
cerr << "Cupboard1 behaves as expected\n";
}
try
{
cerr << "Creating Cupboard2\n";
Cupboard2{};
cerr << "Beyond Cupboard2 object\n";
}
catch (...)
{
cerr << "Cupboard2 behaves as expected\n";
}
}
When this program is run it produces the following output:
Creating Cupboard1
Drawer 1 used
Cupboard1 behaves as expected
Creating Cupboard2
Drawer 2 used
Drawer 1 used
terminate called after throwing an instance of 'int'
Abort
The final Abort indicates that the program has aborted instead of
displaying a message like Cupboard2 behaves as expected.
Let's have a look at the three classes involved. The class Drawer has no
particular characteristics, except that its destructor throws an exception:
class Drawer
{
size_t d_nr;
public:
Drawer(size_t nr)
:
d_nr(nr)
{}
~Drawer()
{
cerr << "Drawer " << d_nr << " used\n";
throw 0;
}
};
The class Cupboard1 has no special characteristics at all. It merely
has a single composed Drawer object:
class Cupboard1
{
Drawer left;
public:
Cupboard1()
:
left(1)
{}
};
The class Cupboard2 is constructed comparably, but it has two
composed Drawer objects:
class Cupboard2
{
Drawer left;
Drawer right;
public:
Cupboard2()
:
left(1),
right(2)
{}
};
When Cupboard1's destructor is called Drawer's destructor is
eventually called to destroy its composed object. This destructor throws an
exception, which is caught beyond the program's first try block. This
behavior is completely as expected.
A subtlety here is that Cupboard1's destructor (and hence Drawer's
destructor) is activated immediately subsequent to its construction. Its
destructor is called immediately subsequent to its construction as
Cupboard1() defines an anonymous object. As a result the Beyond
Cupboard1 object text is never inserted into std::cerr.
Because of Drawer's destructor throwing an exception a problem occurs
when Cupboard2's destructor is called. Of its two composed objects, the
second Drawer's destructor is called first. This destructor throws an
exception, which ought to be caught beyond the program's second try
block. However, although the flow of control by then has left the context of
Cupboard2's destructor, that object hasn't completely been destroyed yet
as the destructor of its other (left) Drawer still has to be called.
Normally that would not be a big problem: once an exception is thrown from
Cupboard2's destructor any remaining actions would simply be ignored,
albeit that (as both drawers are properly constructed objects) left's
destructor would still have to be called.
This happens here too and left's destructor also needs to throw an
exception. But as we've already left the context of the second try block,
the current flow control is now thoroughly mixed up, and the program has no
other option but to abort. It does so by calling terminate(), which in
turn calls abort(). Here we have our collapsing cupboard having two
drawers, even though the cupboard having one drawer behaves perfectly.
The program aborts since there are multiple composed objects whose destructors throw exceptions leaving the destructors. In this situation one of the composed objects would throw an exception by the time the program's flow control has already left its proper context causing the program to abort.
The C++ standard therefore understandably stipulates that exceptions
may never leave destructors. Here is the skeleton of a destructor whose
code might throw
exceptions. No function try block but all the destructor's actions are
encapsulated in a try block nested under the destructor's body.
Class::~Class()
{
try
{
maybe_throw_exceptions();
}
catch (...)
{}
}