The reader should be forewarned that extensive knowledge of the C programming language is actually assumed. The C++ Annotations continue where topics of the C programming language end, such as pointers, basic flow control and the construction of functions.
Some elements of the language, like specific lexical tokens (like
digraphs (e.g., <: for [, and >: for ])) are not covered
by the C++ Annotations, as these tokens occur extremely seldom in C++ source
code. In addition, trigraphs (using ??< for {, and ??> for
}) have been removed from C++.
The working draft of the C++ standard is freely available, and can be cloned from the git-repository at https://gitlab.com/cplusplus/draft.git
The version number of the C++ Annotations (currently 12.2.0) is updated when the content of the document change. The first number is the major number, and is probably not going to change for some time: it indicates a major rewriting. The middle number is increased when new information is added to the document. The last number only indicates small changes; it is increased when, e.g., series of typos are corrected.
This document is published by the Center of Information Technology, University of Groningen, the Netherlands under the GNU General Public License.
The C++ Annotations were typeset using the yodl formatting system.
All correspondence concerning suggestions, additions, improvements or changes to this document should be directed to the author:
Frank B. Brokken
University of Groningen,
PO Box 407,
9700 AK Groningen
The Netherlands
(email: f.b.brokken@rug.nl)
In this chapter an overview of C++'s defining features is presented. A few extensions to C are reviewed and the concepts of object based and object oriented programming (OOP) are briefly introduced.
std::iterator is
deprecated. Section 22.14 was rewritten; section
11.1 was updated (operator[] const should return
Type const & instead of Type values); added section
5.3 covering std::string_view; added section
20.15 covering synchronization of output to streams in
multi-threaded programs; added sections 22.10.2.1 and
23.13.7.2 about bound-friends; 'typedef' definitions were
replaced by 'using' declarations.
__file_clock::to_sys
static member (section 4.3.1), repaired the descriptions
of pop*() members of various abstract containers, and reorganized
the description of the facilities of the filesystem::path class.
std::optional class
is used to return values from functions that are optionally available,
std::iota is used to fill a range with a sequence of incremented
values.
C++20 concepts.
C++20 standard.
error_codes, error_categories,
and error_conditions (cf. sections 4.3.2,
10.9, and 23.7).
C++20 standard. Version 11.0.0 is made available at
the time the C++20 standard has not yet formally been released, and
compilers do not yet implement all its new elements. Therefore,
modifications and updates may be required once the C++20 standard has
officially become the next standard. However, the elements of the new
standard that are now covered by the C++ Annotations are (mostly)
supported by compilers.
std::filesystem namespace
received a new subsection showing which facilities of the
std::filesystem namespace are replacing traditional C
functions.
std::tuple elements in combination with
structured binding declarations.
C++ was originally a `pre-compiler', similar to the preprocessor of C,
converting special constructions in its source code to plain C. Back then
this code was compiled by a standard C compiler. The `pre-code', which was
read by the C++ pre-compiler, was usually located in a file with the
extension .cc, .C or .cpp. This file would then be converted to a
C source file with the extension .c, which was thereupon compiled and
linked.
The nomenclature of C++ source files remains: the extensions .cc and
.cpp are still used. However, the preliminary work of a C++
pre-compiler is nowadays usually performed during the actual compilation
process. Often compilers determine the language used in a source file from its
extension. This holds true for Borland's and Microsoft's C++ compilers,
which assume a C++ source for an extension .cpp. The GNU
compiler g++, which is available on many Unix platforms, assumes for
C++ the extension .cc.
The fact that C++ used to be compiled into C code is also visible
from the fact that C++ is a superset of C: C++ offers the full
C grammar and supports all C-library functions, and adds to this
features of its own. This makes the transition from C to
C++ quite easy. Programmers familiar with C may start
`programming in C++' by using source files having extensions .cc or
.cpp instead of .c, and may then comfortably slip into all the
possibilities offered by C++. No abrupt change of habits is required.
LaTeX. After some time, Karel rewrote the
text and converted the guide to a more suitable format and (of course) to
English in September 1994.
The first version of the guide appeared on the net in October 1994. By then it
was converted to SGML.
Gradually new chapters were added, and the content was modified and further improved (thanks to countless readers who sent us their comments).
In major version four Frank added new chapters and converted the document from SGML to yodl.
The C++ Annotations are freely distributable. Be sure to read the legal notes.If you like this document, tell your friends about it. Even better, let us know by sending email to Frank.Reading the annotations beyond this point implies that you are aware of these notes and that you agree with them.
.cc and run it through
a C++ compiler:
sizeof('c') equals sizeof(int), 'c' being
any ASCII character. The underlying philosophy is probably that chars,
when passed as arguments to functions, are passed as integers
anyway. Furthermore, the C compiler handles a character constant like
'c' as an integer constant. Hence, in C, the function calls
putchar(10);
and
putchar('\n');
are synonymous.
By contrast, in C++, sizeof('c') is always 1 (but see also section
3.4.2). An int is still an int, though. As we shall see later
(section 2.5.4), the two function calls
somefunc(10);
and
somefunc('\n');
may be handled by different functions: C++ distinguishes functions not
only by their names, but also by their argument types, which are different in
these two calls. The former using an int argument, the latter a char.
void func();
means that a function func() exists, returning no value. The
declaration doesn't specify which arguments (if any) are accepted by the
function.
However, in C++ the above declaration means that the function func()
does not accept any arguments at all. Any arguments passed to it
result in a compile-time error.
Note that the keyword extern is not required when declaring functions. A
function definition becomes a function declaration simply by replacing a
function's body by a semicolon. The keyword extern is required,
though, when declaring variables.
Always use the latest C++ standard supported by your compiler. When the
latest standard isn't used by default, but is already partially implemented it
can usually be selected by specifying the appropriate flag. E.g., to use the
C++20 standard specify the flag --std=c++20. In the
C++ Annotations it is assumed that this flag is used when compiling the
examples.
g++ compiler
(see also https://docs.microsoft.com/en-us/windows/wsl/about).
The GNU g++ compiler's official home page is
http://gcc.gnu.org, also containing
information about how to install the compiler in an MS-Windows system.
source.cc':
g++ source.cc
This produces a binary program (a.out or a.exe). If the default
name is inappropriate, the name of the executable can be specified using the
-o flag (here producing the program source):
g++ -o source source.cc
If a mere compilation is required, the compiled module can be produced using
the -c flag:
g++ -c source.cc
This generates the file source.o, which can later on be linked to
other modules.
C++ programs quickly become too complex to maintain `by hand'. With all
serious programming projects program maintenance tools are used. Usually the
standard make program is used to maintain C++ programs, but good
alternatives exist, like the
icmake
or ccbuild program
maintenance utilities.
It is strongly advised to start using maintenance utilities early in the study of C++.
Concerning the above allegations of C++, we support the following, however.
structs, typedefs etc.. From these types other types
can be derived, thus leading to structs containing structs and so
on. In C++ these facilities are augmented by defining data types which are
completely `self supporting', taking care of, e.g., their memory management
automatically (without having to resort to an independently operating memory
management system as used in, e.g., Java).
xmalloc and xrealloc are used (allocating the memory or aborting
the program when the memory pool is exhausted). However, with functions like
malloc it is easy to err. Frequently errors in C programs can be
traced back to miscalculations when using malloc. Instead, C++
offers facilities to allocate memory in a somewhat safer way, using its
operator new.
static variables can be used and special
data types such as structs can be manipulated by dedicated functions.
Using such techniques, data hiding can be implemented even in C; though it
must be admitted that C++ offers special syntactic constructions, making
it far easier to implement `data hiding' (and more in general:
`encapsulation') in C++ than in C.
With the C++ Annotations we hope to help the reader when transiting from C to C++ by focusing on the additions of C++ as compared to C and by leaving out plain C. It is our hope that you like this document and may benefit from it.
Enjoy and good luck on your journey into C++!
static).
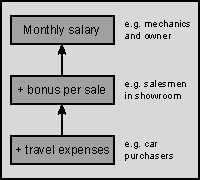
In contrast (or maybe better: in addition) to this, an object-based approach identifies the keywords used in a problem statement. These keywords are then depicted in a diagram where arrows are drawn between those keywords to depict an internal hierarchy. The keywords become the objects in the implementation and the hierarchy defines the relationship between these objects. The term object is used here to describe a limited, well-defined structure, containing all information about an entity: data types and functions to manipulate the data. As an example of an object oriented approach, an illustration follows:
The employees and owner of a car dealer and auto garage company are paid as follows. First, mechanics who work in the garage are paid a certain sum each month. Second, the owner of the company receives a fixed amount each month. Third, there are car salesmen who work in the showroom and receive their salary each month plus a bonus per sold car. Finally, the company employs second-hand car purchasers who travel around; these employees receive their monthly salary, a bonus per bought car, and a restitution of their travel expenses.When representing the above salary administration, the keywords could be mechanics, owner, salesmen and purchasers. The properties of such units are: a monthly salary, sometimes a bonus per purchase or sale, and sometimes restitution of travel expenses. When analyzing the problem in this manner we arrive at the following representation:
In the hierarchy of objects we would define the dependency between the first two objects by letting the car salesmen be `derived' from the owner and mechanics.
The overall process in the definition of a hierarchy such as the above starts with the description of the most simple type. Traditionally (and still encountered with some popular object oriented languages) more complex types are thereupon derived from the basic type, with each derived type adding some new functionality. From these derived types, more complex types can again be derived ad infinitum, until a representation of the entire problem can be made.
Over the years this approach has become less popular in C++ as it typically results in very tight coupling among those types, which in turns reduces rather than enhances the understanding, maintainability and testability of complex programs. The term coupling refers to the degree of independence between software components: tight coupling means a strong dependency, which is frowned upon in C++. In C++ object oriented programs more and more favor small, easy to understand hierarchies, limited coupling and a developmental process where design patterns (cf. Gamma et al. (1995)) play a central role.
In C++ classes are frequently used to define the characteristics of objects. Classes contain the necessary functionality to do useful things. Classes generally do not offer all their functionality (and typically none of their data) to objects of other classes. As we will see, classes tend to hide their properties in such a way that they are not directly modifiable by the outside world. Instead, dedicated functions are used to reach or modify the properties of objects. Thus class-type objects are able to uphold their own integrity. The core concept here is encapsulation of which data hiding is just an example. These concepts are further elaborated in chapter 7.
main:
int main() and int main(int argc, char **argv).
Notes:
main is int, and not void;
main cannot be overloaded (for other than the
abovementioned signatures);
return statement at the
end of main. If omitted main returns 0;
argv[argc] equals 0;
char **envp parameter' is not defined by the C++
standard and should be avoided. Instead, the global variable
extern char **environ should be declared providing access to the program's
environment variables. Its final element has the value 0;
main function
returns. Using a function try block (cf. section 10.11) for main
is also considered a normal end of a C++ program. When a C++ ends
normally, destructors (cf. section 9.2) of globally defined
objects are activated. A function like exit(3) does not normally end
a C++ program and using such functions is therefore deprecated.
// and ends
at the end-of-line marker. The standard C comment, delimited by /* and
*/ can still be used in C++:
int main()
{
// this is end-of-line comment
// one comment per line
/*
this is standard-C comment, covering
multiple lines
*/
}
Despite the example, it is advised not to use C type comment
inside the body of C++ functions. Sometimes existing code must temporarily
be suppressed, e.g., for testing purposes. In those cases it's very practical
to be able to use standard C comment. If such suppressed code itself
contains such comment, it would result in nested comment-lines, resulting in
compiler errors. Therefore, the rule of thumb is not to use C type
comment inside the body of C++ functions (alternatively, #if 0 until
#endif pair of preprocessor directives could of course also be used).
int main()
{
printf("Hello World\n");
}
often compiles under C, albeit with a warning that printf()
is an unknown function. But C++ compilers (should) fail to produce code in
such cases. The error is of course caused by the missing
#include <stdio.h> (which in C++ is more commonly included as
#include <cstdio> directive).
And while we're at it: as we've seen in C++ main always uses
the int return value. Although it is possible to define int
main() without explicitly defining a return statement, within main it is
not possible to use a return statement without an explicit
int-expression. For example:
int main()
{
return; // won't compile: expects int expression, e.g.
// return 1;
}
Implicit conversions from void * to non-void pointers are not
allowed. E.g., the following isn't accepted in C++:
void *none()
{
return 0;
}
int main()
{
int *empty = none();
}
const attribute). An example is given
below:
#include <stdio.h>
void show(int val)
{
printf("Integer: %d\n", val);
}
void show(double val)
{
printf("Double: %lf\n", val);
}
void show(char const *val)
{
printf("String: %s\n", val);
}
int main()
{
show(12);
show(3.1415);
show("Hello World!\n");
}
In the above program three functions show are defined, only differing
in their parameter lists, expecting an int, double and char *,
respectively. The functions have identical names. Functions having identical
names but different parameter lists are called overloaded. The act of
defining such functions is called `function overloading'.
The C++ compiler implements function overloading in a rather simple
way. Although the functions share their names (in this example show), the
compiler (and hence the linker) use quite different names. The conversion of a
name in the source file to an internally used name is called
`name mangling'. E.g., the C++ compiler might convert the prototype
void show (int) to the internal name VshowI, while an
analogous function having a char * argument might be called
VshowCP. The actual names that are used internally depend on the compiler
and are not relevant for the programmer, except where these names show up in
e.g., a listing of the content of a library.
Some additional remarks with respect to function overloading:
show are still
somewhat related (they print information to the screen).
However, it is also quite possible to define two functions lookup,
one of which would find a name in a list while the other would determine the
video mode. In this case the behavior of those two functions have nothing in
common. It would therefore be more practical to use names which suggest their
actions; say, findname and videoMode.
printf("Hello World!\n");
provides no information about the return value of the function
printf. Two functions printf which only differ in their
return types would therefore not be distinguishable to the compiler.
const member functions is
introduced (cf. section 7.7). Here it is merely mentioned
that classes normally have so-called member functions associated with them
(see, e.g., chapter 5 for an informal introduction to the
concept). Apart from
overloading member functions using different parameter lists, it
is then also possible to
overload member functions by their const attributes. In those cases,
classes may have pairs of identically named member functions, having identical
parameter lists. Then, these functions are overloaded by their const
attribute. In such cases only one of these functions must have the const
attribute.
#include <stdio.h>
void showstring(char *str = "Hello World!\n");
int main()
{
showstring("Here's an explicit argument.\n");
showstring(); // in fact this says:
// showstring("Hello World!\n");
}
The possibility to omit arguments in situations where default arguments are defined is just a nice touch: it is the compiler who supplies the lacking argument unless it is explicitly specified at the call. The code of the program will neither be shorter nor more efficient when default arguments are used.
Functions may be defined with more than one default argument:
void two_ints(int a = 1, int b = 4);
int main()
{
two_ints(); // arguments: 1, 4
two_ints(20); // arguments: 20, 4
two_ints(20, 5); // arguments: 20, 5
}
When the function two_ints is called, the compiler supplies one or two
arguments whenever necessary. A statement like two_ints(,6) is, however,
not allowed: when arguments are omitted they must be on the right-hand side.
Default arguments must be known at compile-time since at that moment arguments are supplied to functions. Therefore, the default arguments must be mentioned at the function's declaration, rather than at its implementation:
// sample header file
void two_ints(int a = 1, int b = 4);
// code of function in, say, two.cc
void two_ints(int a, int b)
{
...
}
It is an error to supply default arguments in both function definitions and function declarations. When applicable default arguments should be provided in function declarations: when the function is used by other sources the compiler commonly reads the header file rather than the function definition itself. Consequently the compiler has no way to determine the values of default arguments if they are provided in the function definition.
0. In C NULL is often used
in the context of pointers. This difference is purely stylistic, though one
that is widely adopted. In C++ NULL should be avoided (as it is a
macro, and macros can --and therefore should-- easily be avoided in
C++, see also section 8.1.4). Instead 0 can almost always be
used.
Almost always, but not always. As C++ allows function overloading (cf. section 2.5.4) the programmer might be confronted with an unexpected function selection in the situation shown in section 2.5.4:
#include <stdio.h>
void show(int val)
{
printf("Integer: %d\n", val);
}
void show(double val)
{
printf("Double: %lf\n", val);
}
void show(char const *val)
{
printf("String: %s\n", val);
}
int main()
{
show(12);
show(3.1415);
show("Hello World!\n");
}
In this situation a programmer intending to call show(char const *) might
call show(0). But this doesn't work, as 0 is interpreted as int and so
show(int) is called. But calling show(NULL) doesn't work either, as
C++ usually defines NULL as 0, rather than ((void *)0). So,
show(int) is called once again. To solve these kinds of problems the new
C++ standard introduces the keyword nullptr representing the 0
pointer. In the current example the programmer should call show(nullptr)
to avoid the selection of the wrong function. The nullptr value can also
be used to initialize pointer variables. E.g.,
int *ip = nullptr; // OK
int value = nullptr; // error: value is no pointer
void func();
means that the argument list of the declared function is not prototyped: for
functions using this prototype the compiler does not warn against calling
func with any set of arguments. In C the keyword void is used when
it is the explicit intent to declare a function with no arguments at all, as
in:
void func(void);
As C++ enforces strict type checking, in C++ an empty parameter
list indicates the total absence of parameters. The keyword void is
thus omitted.
__cplusplus: it is as if each source file were prefixed with the
preprocessor directive #define __cplusplus.
We shall see examples of the usage of this symbol in the following sections.
As an example, the following code fragment declares a function xmalloc
as a C function:
extern "C" void *xmalloc(int size);
This declaration is analogous to a declaration in C, except that the
prototype is prefixed with extern "C".
A slightly different way to declare C functions is the following:
extern "C"
{
// C-declarations go in here
}
It is also possible to place preprocessor directives at the location of
the declarations. E.g., a C header file myheader.h which declares
C functions can be included in a C++ source file as follows:
extern "C"
{
#include <myheader.h>
}
Although these two approaches may be used, they are actually seldom encountered in C++ sources. A more frequently used method to declare external C functions is encountered in the next section.
__cplusplus and the
possibility to define extern "C" functions offers the ability to
create header files for both C and C++. Such a header file might,
e.g., declare a group of functions which are to be used in both C and
C++ programs.
The setup of such a header file is as follows:
#ifdef __cplusplus
extern "C"
{
#endif
/* declaration of C-data and functions are inserted here. E.g., */
void *xmalloc(int size);
#ifdef __cplusplus
}
#endif
Using this setup, a normal C header file is enclosed by extern "C"
{ which occurs near the top of the file and by }, which occurs near
the bottom of the file. The #ifdef directives test for the type of the
compilation: C or C++. The `standard' C header files, such as
stdio.h, are built in this manner and are therefore usable for both C
and C++.
In addition C++ headers should support include guards.
In C++ it is usually undesirable to include the same header file twice in
the same source file. Such multiple inclusions can easily be avoided by
including an #ifndef directive in the header file. For example:
#ifndef MYHEADER_H_
#define MYHEADER_H_
// declarations of the header file is inserted here,
// using #ifdef __cplusplus etc. directives
#endif
When this file is initially scanned by the preprocessor, the symbol
MYHEADER_H_ is not yet defined. The #ifndef condition succeeds and all
declarations are scanned. In addition, the symbol MYHEADER_H_ is defined.
When this file is scanned next while compiling the same source file,
the symbol MYHEADER_H_ has been defined and consequently all information
between the #ifndef and #endif directives is skipped by the compiler.
In this context the symbol name MYHEADER_H_ serves only for
recognition purposes. E.g., the name of the header file can be used for this
purpose, in capitals, with an underscore character instead of a dot.
Apart from all this, the custom has evolved to give C header files the
extension .h, and to give C++ header files no extension. For
example, the standard iostreams cin, cout and cerr are available
after including the header file iostream, rather
than iostream.h. In the Annotations this convention is used
with the standard C++ header files, but not necessarily everywhere else.
There is more to be said about header files. Section 7.11 provides
an in-depth discussion of the preferred organization of C++ header files.
In addition, starting with the C++20 standard modules are available
resulting in a somewhat more efficient way of handling declarations than
offered by the traditional header files.
Currently, the C++ Annotations very briefly covers modules (cf. section 7.11.2).
for-statement, but
also all situations where a variable is only needed, say, half-way through the
function.
If considered appropriate, nested blocks can be used to localize
auxiliary variables. However, situations exist where local variables are
considered appropriate inside nested statements. The just mentioned for
statement is of course a case in point, but local variables can also be
defined within the condition clauses of if-else statements, within
selection clauses of switch statements and condition clauses of while
statements. Variables thus defined are available to the full
statement, including its nested statements. For example, consider the
following switch statement:
#include <stdio.h>
int main()
{
switch (int c = getchar())
{
case 'a':
case 'e':
case 'i':
case 'o':
case 'u':
printf("Saw vowel %c\n", c);
break;
case EOF:
printf("Saw EOF\n");
break;
case '0' ... '9':
printf("Saw number character %c\n", c);
break;
default:
printf("Saw other character, hex value 0x%2x\n", c);
}
}
Note the location of the definition of the character `c': it is
defined in the expression part of the switch statement. This implies
that `c' is available only to the switch statement itself,
including its nested (sub)statements, but not outside the scope of the
switch.
The same approach can be used with if and while statements: a
variable that is defined in the condition clause of an if and while
statement is available in their nested statements. There are some caveats,
though:
if or while statement,
the value of the variable must be interpretable as either zero (false) or
non-zero (true). Usually this is no problem, but in C++ objects (like
objects of the type std::string (cf. chapter 5)) are often
returned by functions. Such objects may or may not be interpretable as numeric
values. If not (as is the case with std::string objects), then such
variables can not be defined at the condition or expression clauses of
condition- or repetition statements. The following example will therefore
not compile:
if (std::string myString = getString()) // assume getString returns
{ // a std::string value
// process myString
}
The above example requires additional clarification. Often a variable can profitably be given local scope, but an extra check is required immediately following its initialization. The initialization and the test cannot both be combined in one expression. Instead two nested statements are required. Consequently, the following example won't compile either:
if ((int c = getchar()) && strchr("aeiou", c))
printf("Saw a vowel\n");
If such a situation occurs, either use two nested if statements, or
localize the definition of int c using a nested compound statement:
if (int c = getchar()) // nested if-statements
if (strchr("aeiou", c))
printf("Saw a vowel\n");
{ // nested compound statement
int c = getchar();
if (c && strchr("aeiou", c))
printf("Saw a vowel\n");
}
typedef is still used in C++, but is not required
anymore when defining union, struct or enum definitions.
This is illustrated in the following example:
struct SomeStruct
{
int a;
double d;
char string[80];
};
When a struct, union or other compound type is defined, the tag of
this type can be used as type name (this is SomeStruct in the above
example):
SomeStruct what;
what.d = 3.1415;
A definition of a struct Point is provided by the code fragment below.
In this structure, two int data fields and one function draw are
declared.
struct Point // definition of a screen-dot
{
int x; // coordinates
int y; // x/y
void draw(); // drawing function
};
A similar structure could be part of a painting program and could, e.g.,
represent a pixel. With respect to this struct it should be noted that:
draw mentioned in the struct definition is a
mere declaration. The actual code of the function defining the actions
performed by the function is found elsewhere (the concept of functions inside
structs is further discussed in section 3.2).
struct Point is equal to the size of its
two ints. A function declared inside the structure does not affect its
size. The compiler implements this behavior by allowing the function
draw to be available only in the context of a Point.
Point structure could be used as follows:
Point a; // two points on
Point b; // the screen
a.x = 0; // define first dot
a.y = 10; // and draw it
a.draw();
b = a; // copy a to b
b.y = 20; // redefine y-coord
b.draw(); // and draw it
As shown in the above example a function that is part of the structure may
be selected using the dot (.) (the arrow (->) operator is used when
pointers to objects are available). This is therefore identical to the way
data fields of structures are selected.
The idea behind this syntactic construction is that several types may
contain functions having identical names. E.g., a structure representing a
circle might contain three int values: two values for the coordinates of
the center of the circle and one value for the radius. Analogously to the
Point structure, a Circle may now have a function draw to draw the
circle.
and and or, not
defined. C++ changed this for postfix expressions, assignment expressions
(including compound assignments), and shift operators:
variable++++ does not compile)).
In the following examples first is evaluated before second, before
third, before fourth, whether they are single variables, parenthesized
expressions, or function calls:
first.second
fourth += third = second += first
first << second << third << fourth
first >> second >> third >> fourth
In addition, when overloading an operator, the function implementing the overloaded operator is evaluated like the built-in operator it overloads, and not in the way function calls are generally ordered.