Next: New Features in 5.2.13 Up: Main Reference Previous: New Features in 7.2.0 Contents Index
In addition to being permitted in the Job resource, the nextpool=xxx specification can be specified as a run override in the run directive of a Schedule resource. Any nextpool specification in a run directive will override any other specification in either the Job or the Pool.
In general, more information is displayed in the Job log on exactly which Next Pool specification is ultimately used.
If you want the old behavior (always display all storage resources) simply add the keyword select to the command – i.e. use status select storage.
Scheduled Jobs: Level Type Pri Scheduled Job Name Schedule ====================================================================== Differential Backup 10 Sun 30-Mar 23:05 BackupClient1 WeeklyCycle Incremental Backup 10 Mon 24-Mar 23:05 BackupClient1 WeeklyCycle Incremental Backup 10 Tue 25-Mar 23:05 BackupClient1 WeeklyCycle ... Full Backup 11 Mon 24-Mar 23:10 BackupCatalog WeeklyCycleAfterBackup Full Backup 11 Wed 26-Mar 23:10 BackupCatalog WeeklyCycleAfterBackup ... ====
Note, the output is listed by the Jobs found, and is not sorted chronologically.
This command has a number of options, most of which act as filters:
The digest algorithm was set to SHA1 or SHA256 depending on the local OpenSSL options. We advise you to not modify the PkiDigest default setting. Please, refer to OpenSSL documentation to know about pro and cons on these options.
FileDaemon {
...
PkiCipher = AES256
}
purge volume action=truncate storage=File pool=Default
The above command is now simplified to be:
truncate storage=File pool=Default
For example, if you have the following backup Jobs in your catalog:
+-------+---------+-------+----------+----------+-----------+ | JobId | Name | Level | JobFiles | JobBytes | JobStatus | +-------+---------+-------+----------+----------+-----------+ | 1 | Vbackup | F | 1754 | 50118554 | T | | 2 | Vbackup | I | 1 | 4 | T | | 3 | Vbackup | I | 1 | 4 | T | | 4 | Vbackup | D | 2 | 8 | T | | 5 | Vbackup | I | 1 | 6 | T | | 6 | Vbackup | I | 10 | 60 | T | | 7 | Vbackup | I | 11 | 65 | T | | 8 | Save | F | 1758 | 50118564 | T | +-------+---------+-------+----------+----------+-----------+
and you want to consolidate only the first 3 jobs and create a virtual backup equivalent to Job 1 + Job 2 + Job 3, you will use jobid=3 in the run command, then Bacula will select the previous Full backup, the previous Differential (if any) and all subsequent Incremental jobs.
run job=Vbackup jobid=3 level=VirtualFull
If you want to consolidate a specific job list, you must specify the exact list of jobs to merge in the run command line. For example, to consolidate the last Differential and all subsequent Incremental, you will use jobid=4,5,6,7 or jobid=4-7 on the run command line. As one of the Job in the list is a Differential backup, Bacula will set the new job level to Differential. If the list is composed only with Incremental jobs, the new job will have a level set to Incremental.
run job=Vbackup jobid=4-7 level=VirtualFull
When using this feature, Bacula will automatically discard jobs that are not related to the current Job. For example, specifying jobid=7,8, Bacula will discard JobId 8 because it is not part of the same backup Job.
We do not recommend it, but really want to consolidate jobs that have different names (so probably different clients, filesets, etc...), you must use alljobid= keyword instead of jobid=.
run job=Vbackup alljobid=1-3,6-8 level=VirtualFull
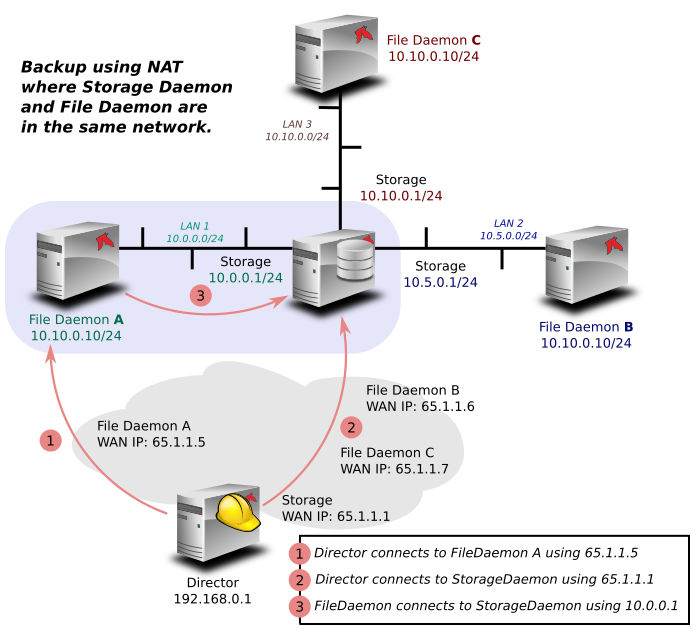
When the Director is behind a NAT, in a WAN area, to connect to the StorageDaemon, the Director uses an “external” ip address, and the FileDaemon should use an “internal” IP address to contact the StorageDaemon.
The normal way to handle this situation is to use a canonical name such as “storage-server” that will be resolved on the Director side as the WAN address and on the Client side as the LAN address. This is now possible to configure this parameter using the new directive FDStorageAddress in the Storage or Client resource.
Storage {
Name = storage1
Address = 65.1.1.1
FD Storage Address = 10.0.0.1
SD Port = 9103
...
}
Client {
Name = client1
Address = 65.1.1.2
FD Storage Address = 10.0.0.1
FD Port = 9102
...
}
Note that using the Client FDStorageAddress directive will not allow to use multiple Storage Daemon, all Backup or Restore requests will be sent to the specified FDStorageAddress.
The new Job Bandwidth Limitation directive may be added to the File daemon's and/or Director's configuration to limit the bandwidth used by a Job on a Client. It can be set in the File daemon's conf file for all Jobs run in that File daemon, or it can be set for each Job in the Director's conf file. The speed is always specified in bytes per second.
For example:
FileDaemon {
Name = localhost-fd
Working Directory = /some/path
Pid Directory = /some/path
...
Maximum Bandwidth Per Job = 5Mb/s
}
The above example would cause any jobs running with the FileDaemon to not exceed 5 megabytes per second of throughput when sending data to the Storage Daemon. Note, the speed is always specified in bytes per second (not in bits per second), and the case (upper/lower) of the specification characters is ignored (i.e. 1MB/s = 1Mb/s).
You may specify the following speed parameter modifiers: k/s (1,000 bytes per second), kb/s (1,024 bytes per second), m/s (1,000,000 bytes per second), or mb/s (1,048,576 bytes per second).
For example:
Job {
Name = locahost-data
FileSet = FS_localhost
Accurate = yes
...
Maximum Bandwidth = 5Mb/s
...
}
The above example would cause Job localhost-data to not exceed 5MB/s of throughput when sending data from the File daemon to the Storage daemon.
A new console command setbandwidth permits to set dynamically the maximum throughput of a running Job or for future jobs of a Client.
* setbandwidth limit=1000 jobid=10
Please note that the value specified for the limit command line parameter is always in units of 1024 bytes (i.e. the number is multiplied by 1024 to give the number of bytes per second). As a consequence, the above limit of 1000 will be interpreted as a limit of 1000 * 1024 = 1,024,000 bytes per second.
This project was funded by Bacula Systems.
The default value is set to 0 (zero), which means there is no limit on the number of read jobs. Note, limiting the read jobs does not apply to Restore jobs, which are normally started by hand. A reasonable value for this directive is one half the number of drives that the Storage resource has rounded down. Doing so, will leave the same number of drives for writing and will generally avoid over committing drives and a deadlock.
The code for this feature was contributed by Bastian Friedrich.
RunAfterJob = "/bin/echo Pid=%P isCloned=%C"
Read Only = yes
* prune expired volumes * prune expired volumes pool=FullPool
To schedule this option automatically, it can be added to the BackupCatalog job definition.
Job {
Name = CatalogBackup
...
RunScript {
Console = "prune expired volume yes"
RunsWhen = Before
}
}
This feature was developed by Josip Almasi, and enhanced to be runtime dynamic by Kern Sibbald.
backup cancel setdebug= setbandwidth= estimate fileset JobId= level = restore endrestore session status .status storage verify RunBeforeNow RunBeforeJob RunAfterJob Run accurate
On or more of these command keywords can be placed in quotes and separated by spaces on the Disable Command directive line. Note: the commands must be written exactly as they appear above.
.bvfs_decode_lstat lstat="A A EHt B A A A JP BAA B BTL/A7 BTL/A7 BTL/A7 A A C" st_nlink=1 st_mode=16877 st_uid=0 st_gid=0 st_size=591 st_blocks=1 st_ino=0 st_ctime=1395650619 st_mtime=1395650619 st_mtime=1395650619 st_dev=0 LinkFI=0
In Bacula Enterprise version 8.0 and later, we introduced new options to the setdebug command.
If the options parameter is set, the following arguments can be used to control debug functions.
| 0 | clear debug flags |
| i | Turn off, ignore bwrite() errors on restore on File Daemon |
| d | Turn off decomp of BackupRead() streams on File Daemon |
| t | Turn on timestamp in traces |
| T | Turn off timestamp in traces |
| c | Truncate trace file if trace file is activated |
| l | Turn on recoding events on P() and V() |
| p | Turn on the display of the event ring when doing a bactrace |
The following command will truncate the trace file and will turn on timestamps in the trace file.
* setdebug level=10 trace=1 options=ct fd
It is now possible to use class of debug messages called tags to control the debug output of Bacula daemons.
| all | Display all debug messages |
| bvfs | Display BVFS debug messages |
| sql | Display SQL related debug messages |
| memory | Display memory and poolmem allocation messages |
| scheduler | Display scheduler related debug messages |
* setdebug level=10 tags=bvfs,sql,memory * setdebug level=10 tags=!bvfs # bacula-dir -t -d 200,bvfs,sql
The tags option is composed of a list of tags, tags are separated by “,” or “+” or “-” or “!”. To disable a specific tag, use “-” or “!” in front of the tag. Note that more tags will come in future versions.