Subsections
Migration and Copy
The term Migration, as used in the context of Bacula, means moving data from one Volume to another. In particular it refers to a Job (similar to a backup job) that reads data that was previously backed up to a Volume and writes it to another Volume. As part of this process, the File catalog records associated with the first backup job are purged. In other words, Migration moves Bacula Job data from one Volume to another by reading the Job data from the Volume it is stored on, writing it to a different Volume in a different Pool, and then purging the database records for the first Job.
The Copy process is essentially identical to the Migration feature with the exception that the Job that is copied is left unchanged. This essentially creates two identical copies of the same backup. However, the copy is treated as a copy rather than a backup job, and hence is not directly available for restore. If bacula founds a copy when a job record is purged (deleted) from the catalog, it will promote the copy as real backup and will make it available for automatic restore. Note: in the text below, to simplify it, we usually speak of a migration job. This, in fact, means either a migration job or a copy job.
The Copy and the Migration jobs run without using the File daemon by copying the data from the old backup Volume to a different Volume in a different Pool.
Please note that in a Migration or Copy Job the Client File daemon is not contacted, thus using a RunScript, it is not possible to run commands on the Client from within the Migration or Copy Job.
The selection process for which Job or Jobs are migrated can be based on quite a number of different criteria such as:
- a single previous Job
- a Volume
- a Client
- a regular expression matching a Job, Volume, or Client name
- the time a Job has been on a Volume
- high and low water marks (usage or occupation) of a Pool
- Volume size
The details of these selection criteria will be defined below.
To run a Migration job, you must first define a Job resource very similar to a Backup Job but with Type = Migrate instead of Type = Backup. One of the key points to remember is that the Pool that is specified for the migration job is the only pool from which jobs will be migrated, with one exception noted below. In addition, the Pool to which the selected Job or Jobs will be migrated is defined by the Next Pool = ... in the Pool resource specified for the Migration Job.
Bacula permits Pools to contain Volumes with different Media Types. However, when doing migration, this is a very undesirable condition. For migration to work properly, you should use Pools containing only Volumes of the same Media Type for all migration jobs.
The migration job normally is either manually started or starts from a Schedule much like a backup job. It searches for a previous backup Job or Jobs that match the parameters you have specified in the migration Job resource, primarily a Selection Type (detailed a bit later). Then for each previous backup JobId found, the Migration Job will run a new Job which copies the old Job data from the previous Volume to a new Volume in the Migration Pool. It is possible that no prior Jobs are found for migration, in which case, the Migration job will simply terminate having done nothing, but normally at a minimum, three jobs are involved during a migration:
- The currently running Migration control Job. This is only a control job for starting the migration child jobs.
- The previous Backup Job (already run). The File records for this Job are purged if the Migration job successfully terminates. The original data remains on the Volume until it is recycled and rewritten.
- A new Migration Backup Job that moves the data from the previous Backup job to the new Volume. If you subsequently do a restore, the data will be read from this Job.
If the Migration control job finds a number of JobIds to migrate (e.g. it is asked to migrate one or more Volumes), it will start one new migration backup job for each JobId found on the specified Volumes. Please note that Migration doesn't scale too well since Migrations are done on a Job by Job basis. This if you select a very large volume or a number of volumes for migration, you may have a large number of Jobs that start. Because each job must read the same Volume, they will run consecutively (not simultaneously).
Bacula version 7.0 and later allows Storage daemon (SD) to Storage daemon (SD) transfer of Copy and Migration Jobs. This permits what is commonly referred to as replication or off-site transfer of Bacula backups. It occurs automatically, if the source SD and destination SD of a Copy or Migration Job are different. The following picture shows how this works. 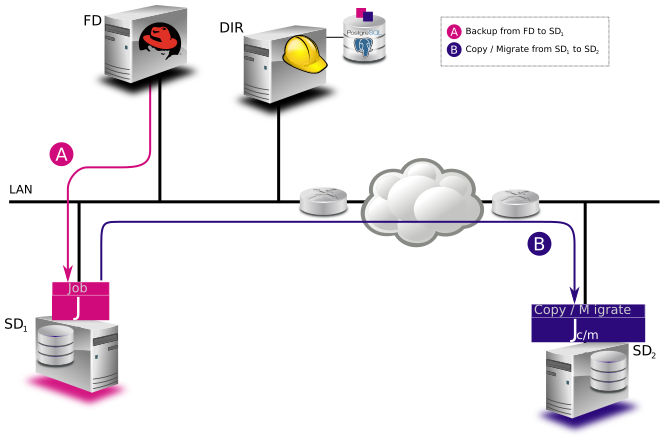
The following directives can appear in a Director's Job resource, and they are used to define a Migration job.
- Pool = Pool-name
- The Pool specified in the Migration control Job is not a new directive for the Job resource, but it is particularly important because it determines what Pool will be examined for finding JobIds to migrate. The exception to this is when Selection Type = SQLQuery, and although a Pool directive must still be specified, no Pool is used, unless you specifically include it in the SQL query. Note, in any case, the Pool resource defined by the Pool directive must contain a Next Pool = ... directive to define the Pool to which the data will be migrated.
- Type = Migrate
- Migrate is a new type that defines the job that is run as being a Migration Job. A Migration Job is a sort of control job and does not have any Files associated with it, and in that sense they are more or less like an Admin job. Migration jobs simply check to see if there is anything to Migrate then possibly start and control new Backup jobs to migrate the data from the specified Pool to another Pool. Note, any original JobId that is migrated will be marked as having been migrated, and the original JobId can no longer be used for restores; all restores will be done from the new migrated Job.
- Type = Copy
- Copy is a new type that defines the job that is run as being a Copy Job. A Copy Job is a sort of control job and does not have any Files associated with it, and in that sense they are more or less like an Admin job. Copy jobs simply check to see if there is anything to Copy then possibly start and control new Backup jobs to copy the data from the specified Pool to another Pool. Note that when a copy is made, the original JobIds are left unchanged. The new copies can not be used for restoration unless you specifically choose them by JobId. Also you subsequently delete a JobId that has a copy, the copy will be automatically upgraded to a Backup rather than a Copy, and it will subsequently be used for restoration.
Once again, a Copy Job cannot be used to restore unless you explicitly specify the Copy JobId during the restore command. If the original backup Job is deleted and there is a Copy of that backup Job, the Copy JobIds will be changed to be backup Jobs that can then be restored.
- Selection Type = Selection-type-keyword
- The Selection-type-keyword determines how the migration job will go about selecting what JobIds to migrate. In most cases, it is used in conjunction with a Selection Pattern to give you fine control over exactly what JobIds are selected. The possible values for Selection-type-keyword are:
- SmallestVolume
- This selection keyword selects the volume with the fewest bytes from the Pool to be migrated. The Pool to be migrated is the Pool defined in the Migration Job resource. The migration control job will then start and run one migration backup job for each of the Jobs found on this Volume. The Selection Pattern, if specified, is not used.
- OldestVolume
- This selection keyword selects the volume with the oldest last write time in the Pool to be migrated. The Pool to be migrated is the Pool defined in the Migration Job resource. The migration control job will then start and run one migration backup job for each of the Jobs found on this Volume. The Selection Pattern, if specified, is not used.
- Client
- The Client selection type, first selects all the Clients that have been backed up in the Pool specified by the Migration Job resource, then it applies the Selection Pattern (defined below) as a regular expression to the list of Client names, giving a filtered Client name list. All jobs that were backed up for those filtered (regexed) Clients will be migrated. The migration control job will then start and run one migration backup job for each of the JobIds found for those filtered Clients.
- Volume
- The Volume selection type, first selects all the Volumes that have been backed up in the Pool specified by the Migration Job resource, then it applies the Selection Pattern (defined below) as a regular expression to the list of Volume names, giving a filtered Volume list. All JobIds that were backed up for those filtered (regexed) Volumes will be migrated. The migration control job will then start and run one migration backup job for each of the JobIds found on those filtered Volumes.
- Job
- The Job selection type, first selects all the Jobs (as defined on the Name directive in a Job resource) that have been backed up in the Pool specified by the Migration Job resource, then it applies the Selection Pattern (defined below) as a regular expression to the list of Job names, giving a filtered Job name list. All JobIds that were run for those filtered (regexed) Job names will be migrated. Note, for a given Job named, they can be many jobs (JobIds) that ran. The migration control job will then start and run one migration backup job for each of the Jobs found.
- SQLQuery
- The SQLQuery selection type, used the Selection Pattern as an SQL query to obtain the JobIds to be migrated. The Selection Pattern must be a valid SELECT SQL statement for your SQL engine, and it must return the JobId as the first field of the SELECT.
- PoolOccupancy
- This selection type will cause the Migration job to compute the total size of the specified pool for all Media Types combined. If it exceeds the Migration High Bytes defined in the Pool, the Migration job will migrate all JobIds beginning with the oldest Volume in the pool (determined by Last Write time) until the Pool bytes drop below the Migration Low Bytes defined in the Pool. This calculation should be consider rather approximate because it is made once by the Migration job before migration is begun, and thus does not take into account additional data written into the Pool during the migration. In addition, the calculation of the total Pool byte size is based on the Volume bytes saved in the Volume (Media) database entries. The bytes calculate for Migration is based on the value stored in the Job records of the Jobs to be migrated. These do not include the Storage daemon overhead as is in the total Pool size. As a consequence, normally, the migration will migrate more bytes than strictly necessary.
- PoolTime
- The PoolTime selection type will cause the Migration job to look at the time each JobId has been in the Pool since the job ended. All Jobs in the Pool longer than the time specified on Migration Time directive in the Pool resource will be migrated.
- PoolUncopiedJobs
- This selection which copies all jobs from a pool to an other pool which were not copied before is available only for copy Jobs.
- Selection Pattern = Quoted-string
- The Selection Patterns permitted for each Selection-type-keyword are described above.
For the OldestVolume and SmallestVolume, this Selection pattern is not used (ignored).
For the Client, Volume, and Job keywords, this pattern must be a valid regular expression that will filter the appropriate item names found in the Pool.
For the SQLQuery keyword, this pattern must be a valid SELECT SQL statement that returns JobIds.
- Purge Migration Job = yes/no
- This directive may be added to the Migration Job definition in the Director configuration file to purge the job migrated at the end of a migration.
The following directives can appear in a Director's Pool resource, and they are used to define a Migration job.
- Migration Time = time-specification
- If a PoolTime migration is done, the time specified here in seconds (time modifiers are permitted – e.g. hours, ...) will be used. If the previous Backup Job or Jobs selected have been in the Pool longer than the specified PoolTime, then they will be migrated.
- Migration High Bytes = byte-specification
- This directive specifies the number of bytes in the Pool which will trigger a migration if a PoolOccupancy migration selection type has been specified. The fact that the Pool usage goes above this level does not automatically trigger a migration job. However, if a migration job runs and has the PoolOccupancy selection type set, the Migration High Bytes will be applied. Bacula does not currently restrict a pool to have only a single Media Type, so you must keep in mind that if you mix Media Types in a Pool, the results may not be what you want, as the Pool count of all bytes will be for all Media Types combined.
- Migration Low Bytes = byte-specification
- This directive specifies the number of bytes in the Pool which will stop a migration if a PoolOccupancy migration selection type has been specified and triggered by more than Migration High Bytes being in the pool. In other words, once a migration job is started with PoolOccupancy migration selection and it determines that there are more than Migration High Bytes, the migration job will continue to run jobs until the number of bytes in the Pool drop to or below Migration Low Bytes.
- Next Pool = pool-specification
- The Next Pool directive specifies the pool to which Jobs will be migrated. This directive is required to define the Pool into which the data will be migrated. Without this directive, the migration job will terminate in error. The Next Pool directive may also be specified in the Job resource or on a Run directive in the Schedule resource. Any Next Pool directive in the Job resource will take precedence over the Pool definition, and any Next Pool specification on the Run directive in a Schedule resource will take ultimate precedence.
- Storage = storage-specification
- The Storage directive specifies what Storage resource will be used for all Jobs that use this Pool. It takes precedence over any other Storage specifications that may have been given such as in the Schedule Run directive, or in the Job resource. We highly recommend that you define the Storage resource to be used in the Pool rather than elsewhere (job, schedule run, ...).
- Each Pool into which you migrate Jobs or Volumes must contain Volumes of only one Media Type.
- Migration takes place on a JobId by JobId basis. That is each JobId is migrated in its entirety and independently of other JobIds. Once the Job is migrated, it will be on the new medium in the new Pool, but for the most part, aside from having a new JobId, it will appear with all the same characteristics of the original job (start, end time, ...). The column RealEndTime in the catalog Job table will contain the time and date that the Migration terminated, and by comparing it with the EndTime column you can tell whether or not the job was migrated. The original job is purged of its File records, and its Type field is changed from "B" to "M" to indicate that the job was migrated.
- Jobs on Volumes will be considered for Migration only if the Volume is marked, Full, Used, or Error. Volumes that are still marked Append will not be considered for migration. This prevents Bacula from attempting to read the Volume at the same time it is writing it. It also reduces other deadlock situations, as well as avoids the problem that you migrate a Volume and later find new files appended to that Volume.
- As noted above, for the Migration High Bytes, the calculation of the bytes to migrate is somewhat approximate.
- If you keep Volumes of different Media Types in the same Pool, it is not clear how well migration will work. We recommend only one Media Type per pool.
- It is possible to get into a resource deadlock where Bacula does not find enough drives to simultaneously read and write all the Volumes needed to do Migrations. For the moment, you must take care as all the resource deadlock algorithms are not yet implemented. You may use the Maximum Concurrent Read Jobs directive to control the drive assignment behavior to reduce resource deadlocks. The MaximumConcurrentReadJobs should have a maximum of one less than one half the number of drives that are available for reading and writing. Doing so, will assure that for each read drive there is one that can write so that the Migration jobs will not stall due to a deadlock.
- Migration is done only when you run a Migration job. If you set a Migration High Bytes and that number of bytes is exceeded in the Pool no migration job will automatically start. You must schedule the migration jobs, and they must run for any migration to take place.
- If you migrate a number of Volumes, a very large number of Migration jobs may start.
- Figuring out what jobs will actually be migrated can be a bit complicated due to the flexibility provided by the regex patterns and the number of different options. Turning on a debug level of 100 or more will provide a limited amount of debug information about the migration selection process.
- Bacula currently does only minimal Storage conflict resolution, so you must take care to ensure that you don't try to read and write to the same device or Bacula may block waiting to reserve a drive that it will never find. In general, ensure that all your migration pools contain only one Media Type, and that you always migrate to pools with different Media Types.
- The Next Pool = ... directive must be defined in the Pool referenced in the Migration Job to define the Pool into which the data will be migrated.
- Pay particular attention to the fact that data is migrated on a Job by Job basis, and for any particular tape Volume, only one Job can read that Volume at a time (no simultaneous read), so migration jobs that all reference the same Volume will run sequentially. This can be a potential bottle neck and does not scale very well to large numbers of jobs.
For disk Volumes, multiple simultaneous Jobs can read the same Volume at the same time, so the above restriction does not apply.
- Only migration of Selection Types of Job and Volume have been carefully tested. All the other migration methods (time, occupancy, smallest, oldest, ...) need additional testing.
- Unless specified otherwise, Plugins are not compatible with Copy/Migration/VirtualFull jobs by default.
When you specify a Migration Job, you must specify all the standard directives as for a Job. However, certain such as the Level, Client, and FileSet, though they must be defined, are ignored by the Migration job because the values from the original job used instead.
As an example, suppose you have the following Job that you run every night. To note: there is no Storage directive in the Job resource; there is a Storage directive in each of the Pool resources; the Pool to be migrated (File) contains a Next Pool directive that defines the output Pool (where the data is written by the migration job).
# Define the backup Job
Job {
Name = "NightlySave"
Type = Backup
Level = Incremental # default
Client=rufus-fd
FileSet="Full Set"
Schedule = "WeeklyCycle"
Messages = Standard
Pool = Default
}
# Default pool definition
Pool {
Name = Default
Pool Type = Backup
AutoPrune = yes
Recycle = yes
Next Pool = Tape
Storage = File
LabelFormat = "File"
}
# Tape pool definition
Pool {
Name = Tape
Pool Type = Backup
AutoPrune = yes
Recycle = yes
Storage = DLTDrive
}
# Definition of File storage device
Storage {
Name = File
Address = rufus
Password = "ccV3lVTsQRsdIUGyab0N4sMDavui2hOBkmpBU0aQKOr9"
Device = "File" # same as Device in Storage daemon
Media Type = File # same as MediaType in Storage daemon
}
# Definition of DLT tape storage device
Storage {
Name = DLTDrive
Address = rufus
Password = "ccV3lVTsQRsdIUGyab0N4sMDavui2hOBkmpBU0aQKOr9"
Device = "HP DLT 80" # same as Device in Storage daemon
Media Type = DLT8000 # same as MediaType in Storage daemon
}
Where we have included only the essential information – i.e. the Director, FileSet, Catalog, Client, Schedule, and Messages resources are omitted.
As you can see, by running the NightlySave Job, the data will be backed up to File storage using the Default pool to specify the Storage as File.
Now, if we add the following Job resource to this conf file.
Job {
Name = "migrate-volume"
Type = Migrate
Level = Full
Client = rufus-fd
FileSet = "Full Set"
Messages = Standard
Pool = Default
Maximum Concurrent Jobs = 4
Selection Type = Volume
Selection Pattern = "File"
}
and then run the job named migrate-volume, all volumes in the Pool named Default (as specified in the migrate-volume Job that match the regular expression pattern File will be migrated to tape storage DLTDrive because the Next Pool in the Default Pool specifies that Migrations should go to the pool named Tape, which uses Storage DLTDrive.
If instead, we use a Job resource as follows:
Job {
Name = "migrate"
Type = Migrate
Level = Full
Client = rufus-fd
FileSet="Full Set"
Messages = Standard
Pool = Default
Maximum Concurrent Jobs = 4
Selection Type = Job
Selection Pattern = ".*Save"
}
All jobs ending with the name Save will be migrated from the File Default to the Tape Pool, or from File storage to Tape storage.
Virtual Backup Consolidation
When the Job Level is set to VirtualFull, it permits you to consolidate the previous Full backup plus the most recent Differential backup and any subsequent Incremental backups into a new Full backup. This new Full backup will then be considered as the most recent Full for any future Incremental or Differential backups. The VirtualFull backup is accomplished without contacting the client by reading the previous backup data and writing it to a volume in a different pool.
Bacula's virtual backup feature is often called Synthetic Backup or Consolidation in other backup products.
In some respects the Virtual Backup feature works similar to a Migration job, in that Bacula normally reads the data from the pool specified in the Job resource, and writes it to the Next Pool specified in the Job resource. Note, this means that usually the output from the Virtual Backup is written into a different pool from where your prior backups are saved. Doing it this way guarantees that you will not get a deadlock situation attempting to read and write to the same volume in the Storage daemon. If you then want to do subsequent backups, you may need to move the Virtual Full Volume back to your normal backup pool. Alternatively, you can set your Next Pool to point to the current pool. This will cause Bacula to read and write to Volumes in the current pool. In general, this will work, because Bacula will not allow reading and writing on the same Volume. In any case, once a VirtualFull has been created, and a restore is done involving the most current Full, it will read the Volume or Volumes by the VirtualFull regardless of in which Pool the Volume is found.
A typical Job resource definition might look like the following:
Job {
Name = "MyBackup"
Type = Backup
Client=localhost-fd
FileSet = "Full Set"
Storage = File
Messages = Standard
Pool = Default
SpoolData = yes
}
# Default pool definition
Pool {
Name = Default
Pool Type = Backup
Volume Retention = 365d # one year
NextPool = Full
Storage = File
}
Pool {
Name = Full
Pool Type = Backup
Volume Retention = 365d # one year
Storage = DiskChanger
}
# Definition of file storage device
Storage {
Name = File
Address = localhost
Password = "xxx"
Device = FileStorage
Media Type = File
Maximum Concurrent Jobs = 5
}
# Definition of DDS Virtual tape disk storage device
Storage {
Name = DiskChanger
Address = localhost # N.B. Use a fully qualified name here
Password = "yyy"
Device = DiskChanger
Media Type = DiskChangerMedia
Maximum Concurrent Jobs = 4
Autochanger = yes
}
Then in bconsole or via a Run schedule, you would run the job as:
run job=MyBackup level=Full
run job=MyBackup level=Incremental
run job=MyBackup level=Differential
run job=MyBackup level=Incremental
run job=MyBackup level=Incremental
So providing there were changes between each of those jobs, you would end up with a Full backup, a Differential, which includes the first Incremental backup, then two Incremental backups. All the above jobs would be written to the Default pool.
To consolidate those backups into a new Full backup, you would run the following:
run job=MyBackup level=VirtualFull
And it would produce a new Full backup without using the client, and the output would be written to the Full Pool which uses the Diskchanger Storage.
If the Virtual Full is run, and there are no prior Jobs, the Virtual Full will fail with an error.
Note, the Start and End time of the Virtual Full backup is set to the values for the last job included in the Virtual Full (in the above example, it is an Increment). This is so that if another incremental is done, which will be based on the Virtual Full, it will backup all files from the last Job included in the Virtual Full rather than from the time the Virtual Full was actually run.
By default Bacula is selecting jobs automatically, however, you may want to choose any point in time to create the Virtual backup. For example, if you have the following Jobs in your catalog:
+-------+---------+-------+----------+----------+-----------+
| JobId | Name | Level | JobFiles | JobBytes | JobStatus |
+-------+---------+-------+----------+----------+-----------+
| 1 | Vbackup | F | 1754 | 50118554 | T |
| 2 | Vbackup | I | 1 | 4 | T |
| 3 | Vbackup | I | 1 | 4 | T |
| 4 | Vbackup | D | 2 | 8 | T |
| 5 | Vbackup | I | 1 | 6 | T |
| 6 | Vbackup | I | 10 | 60 | T |
| 7 | Vbackup | I | 11 | 65 | T |
| 8 | Save | F | 1758 | 50118564 | T |
+-------+---------+-------+----------+----------+-----------+
If you want to consolidate only the first 3 jobs and create a virtual backup equivalent to Job 1 + Job 2 + Job 3, you will use jobid=3 in the run command, then Bacula will select the previous Full backup, the previous Differential (if any) and all subsequent Incremental jobs.
run job=Vbackup jobid=3 level=VirtualFull
If you want to consolidate a specific job list, you must specify the exact list of jobs to merge in the run command line. For example, to consolidate the last Differential and all subsequent Incremental, you will use jobid=4,5,6,7 or jobid=4-7 in the run command line. As one of the Job in the list is a Differential backup, Bacula will set the new job level to Differential. If the list is composed only with Incremental jobs, the new job will have a level set to Incremental.
run job=Vbackup jobid=4-7 level=VirtualFull
When using this feature, Bacula will automatically discard jobs that are not related to the current Job. For example, specifying jobid=7,8, Bacula will discard the jobid 8.
If you know what you are doing and still want to consolidate jobs that have different names (so probably different clients, filesets, etc...), you must use alljobid= keyword instead of jobid=.
run job=Vbackup alljobid=1-3,6-8 level=VirtualFull