Variance of SAXS data#
There has been a long discussion about the validity (or not) of pixel splitting regarding the propagation of errors #520 #882 #883. So we will develop a mathematical model for a SAXS experiment and validate it in the case of a SAXS approximation (i.e. no solid-angle correction, no polarisation effect, and of course small angled \(\theta = sin(\theta) = tan(\theta)\))
System under study#
Let’s do a numerical experiment, simulating the following experiment:
Detector: 1024x1024 square pixels of 100µm each, assumed to be poissonian.
Geometry: The detector is placed at 1m from the sample, the beam center is in the corner of the detector
Intensity: the maximum signal on the detector is 10 000 photons per pixel, each pixel having a minimum count of a hundreed.
Wavelength: 1 Angstrom
During the first part of the studdy, the solid-angle correction will be discarded, same for polarisation corrections.
Since pixel splitting is disabled, many rebinning engines are available and will be benchmarked:
numpy: the slowest available in pyFAI
histogram: implemented in cython
nosplit_csr: using a look-up table
nosplit_csr_ocl_gpu: which offloads the calculation on the GPU.
We will check they all provide the same numerical result
Now we define some constants for the studdy. The dictionary kwarg contains the parameters used for azimuthal integration. This ensures the number of bins for the regrouping or correction like \(\Omega\) and polarization are always the same.
[1]:
%matplotlib inline
# use `widget` instead of `inline` for better user-exeperience. `inline` allows to store plots into notebooks.
import time
start_time = time.perf_counter()
import sys
print(sys.executable)
print(sys.version)
import os
os.environ["PYOPENCL_COMPILER_OUTPUT"] = "0"
/home/jerome/.venv/py311/bin/python3
3.11.2 (main, Nov 30 2024, 21:22:50) [GCC 12.2.0]
[2]:
pix = 100e-6
shape = (1024, 1024)
npt = 1000
nimg = 1000
wl = 1e-10
I0 = 1e4
kwargs = {"npt":npt,
"correctSolidAngle":False,
"polarization_factor":None,
"safe":False}
[3]:
import numpy, numexpr, numba
from scipy.stats import chi2 as chi2_dist
from matplotlib.pyplot import subplots
from matplotlib.colors import LogNorm
import logging
logging.basicConfig(level=logging.ERROR)
import pyFAI
print(f"pyFAI version: {pyFAI.version}")
from pyFAI.detectors import Detector
from pyFAI.method_registry import IntegrationMethod
from pyFAI.gui import jupyter
detector = Detector(pix, pix)
detector.shape = detector.max_shape = shape
print(detector)
pyFAI version: 2025.3.0
Detector Detector PixelSize= 100µm, 100µm BottomRight (3)
We define in ai_init the geometry, the detector and the wavelength.
[4]:
ai_init = {"dist":1.0,
"poni1":0.0,
"poni2":0.0,
"rot1":0.0,
"rot2":0.0,
"rot3":0.0,
"detector":detector,
"wavelength":wl}
ai = pyFAI.load(ai_init)
print(ai)
#Solid consideration:
Ω = ai.solidAngleArray(detector.shape, absolute=True)
print(f"Solid angle: maxi= {Ω.max()} mini= {Ω.min()}, ratio= {Ω.min()/Ω.max()}")
Detector Detector PixelSize= 100µm, 100µm BottomRight (3)
Wavelength= 1.000000e-10 m
SampleDetDist= 1.000000e+00 m PONI= 0.000000e+00, 0.000000e+00 m rot1=0.000000 rot2=0.000000 rot3=0.000000 rad
DirectBeamDist= 1000.000 mm Center: x=0.000, y=0.000 pix Tilt= 0.000° tiltPlanRotation= 0.000° 𝛌= 1.000Å
Solid angle: maxi= 9.999999925000007e-09 mini= 9.69376805173843e-09, ratio= 0.9693768124441684
[5]:
# Validation of the flatness of a flat image integrated
flat = numpy.ones(detector.shape)
res_flat = ai.integrate1d(flat, **kwargs)
crv = jupyter.plot1d(res_flat)
crv.axes.set_ylim(0.9,1.1)
pass

[6]:
#Equivalence of different rebinning engines ... looking for the fastest:
fastest = sys.maxsize
best = None
print(f"| {'Method':70s} | {'error':8s} | {'time(ms)':7s}|")
print("+"+"-"*72+"+"+"-"*10+"+"+"-"*9+"+")
for method in IntegrationMethod.select_method(dim=1):
res_flat = ai.integrate1d(flat, method=method, **kwargs)
#print(f"timeit for {method} max error: {abs(res_flat.intensity-1).max()}")
m = str(method).replace(")","")[26:96]
err = abs(res_flat.intensity-1).max()
tm = %timeit -o -r1 -q ai.integrate1d(flat, method=method, **kwargs)
tm_best = tm.best
print(f"| {m:70s} | {err:6.2e} | {tm_best*1000:7.3f} |")
if tm_best<fastest:
fastest = tm_best
best = method
print("+"+"-"*72+"+"+"-"*10+"+"+"-"*9+"+")
print(f"\nThe fastest method is {best} in {1000*fastest:.3f} ms/1Mpix frame")
| Method | error | time(ms)|
+------------------------------------------------------------------------+----------+---------+
| no split, histogram, python | 0.00e+00 | 32.252 |
| no split, histogram, cython | 0.00e+00 | 12.623 |
| bbox split, histogram, cython | 0.00e+00 | 31.970 |
| full split, histogram, cython | 0.00e+00 | 149.574 |
| no split, CSR, cython | 0.00e+00 | 9.208 |
| bbox split, CSR, cython | 0.00e+00 | 9.036 |
| no split, CSR, python | 0.00e+00 | 11.344 |
| bbox split, CSR, python | 0.00e+00 | 12.988 |
| no split, CSC, cython | 0.00e+00 | 8.461 |
| bbox split, CSC, cython | 0.00e+00 | 11.219 |
| no split, CSC, python | 0.00e+00 | 12.152 |
| bbox split, CSC, python | 0.00e+00 | 15.328 |
| bbox split, LUT, cython | 0.00e+00 | 11.193 |
| no split, LUT, cython | 0.00e+00 | 10.081 |
| full split, LUT, cython | 0.00e+00 | 10.046 |
| full split, CSR, cython | 0.00e+00 | 9.338 |
| full split, CSR, python | 0.00e+00 | 12.940 |
| full split, CSC, cython | 0.00e+00 | 11.568 |
| full split, CSC, python | 0.00e+00 | 14.932 |
| no split, histogram, OpenCL, NVIDIA CUDA / Quadro K2200 | 1.19e-07 | 19.598 |
| no split, histogram, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030 | 1.19e-07 | 5.727 |
1 error generated.
| no split, histogram, OpenCL, Portable Computing Language / pthread-has | 0.00e+00 | 17.716 |
/home/jerome/.venv/py311/lib/python3.11/site-packages/pyopencl/cache.py:496: CompilerWarning: Non-empty compiler output encountered. Set the environment variable PYOPENCL_COMPILER_OUTPUT=1 to see more.
_create_built_program_from_source_cached(
/home/jerome/.venv/py311/lib/python3.11/site-packages/pyopencl/cache.py:500: CompilerWarning: Non-empty compiler output encountered. Set the environment variable PYOPENCL_COMPILER_OUTPUT=1 to see more.
prg.build(options_bytes, devices)
| no split, histogram, OpenCL, Intel(R OpenCL / AMD EPYC 7203P 8-Core Pr | 0.00e+00 | 12.777 |
| bbox split, CSR, OpenCL, NVIDIA CUDA / Quadro K2200 | 1.19e-07 | 3.391 |
| no split, CSR, OpenCL, NVIDIA CUDA / Quadro K2200 | 1.19e-07 | 2.288 |
| bbox split, CSR, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030 | 1.19e-07 | 3.542 |
| no split, CSR, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030 | 1.19e-07 | 3.126 |
| bbox split, CSR, OpenCL, Portable Computing Language / pthread-haswell | 0.00e+00 | 7.973 |
| no split, CSR, OpenCL, Portable Computing Language / pthread-haswell-A | 0.00e+00 | 5.282 |
/home/jerome/.venv/py311/lib/python3.11/site-packages/pyopencl/cache.py:420: CompilerWarning: Non-empty compiler output encountered. Set the environment variable PYOPENCL_COMPILER_OUTPUT=1 to see more.
prg.build(options_bytes, [devices[i] for i in to_be_built_indices])
| bbox split, CSR, OpenCL, Intel(R OpenCL / AMD EPYC 7203P 8-Core Proces | 0.00e+00 | 6.612 |
| no split, CSR, OpenCL, Intel(R OpenCL / AMD EPYC 7203P 8-Core Processo | 0.00e+00 | 5.397 |
| full split, CSR, OpenCL, NVIDIA CUDA / Quadro K2200 | 1.19e-07 | 3.461 |
| full split, CSR, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030 | 1.19e-07 | 3.541 |
| full split, CSR, OpenCL, Portable Computing Language / pthread-haswell | 0.00e+00 | 7.715 |
| full split, CSR, OpenCL, Intel(R OpenCL / AMD EPYC 7203P 8-Core Proces | 0.00e+00 | 6.746 |
| bbox split, LUT, OpenCL, NVIDIA CUDA / Quadro K2200 | 1.19e-07 | 6.304 |
| no split, LUT, OpenCL, NVIDIA CUDA / Quadro K2200 | 1.19e-07 | 4.753 |
| bbox split, LUT, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030 | 1.19e-07 | 5.552 |
| no split, LUT, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030 | 1.19e-07 | 4.664 |
| bbox split, LUT, OpenCL, Portable Computing Language / pthread-haswell | 0.00e+00 | 6.151 |
| no split, LUT, OpenCL, Portable Computing Language / pthread-haswell-A | 0.00e+00 | 5.049 |
| bbox split, LUT, OpenCL, Intel(R OpenCL / AMD EPYC 7203P 8-Core Proces | 0.00e+00 | 7.877 |
| no split, LUT, OpenCL, Intel(R OpenCL / AMD EPYC 7203P 8-Core Processo | 0.00e+00 | 6.729 |
| full split, LUT, OpenCL, NVIDIA CUDA / Quadro K2200 | 1.19e-07 | 5.671 |
| full split, LUT, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030 | 1.19e-07 | 5.505 |
| full split, LUT, OpenCL, Portable Computing Language / pthread-haswell | 0.00e+00 | 5.543 |
| full split, LUT, OpenCL, Intel(R OpenCL / AMD EPYC 7203P 8-Core Proces | 0.00e+00 | 6.449 |
+------------------------------------------------------------------------+----------+---------+
The fastest method is IntegrationMethod(1d int, no split, CSR, OpenCL, NVIDIA CUDA / Quadro K2200) in 2.288 ms/1Mpix frame
[7]:
# so we chose the fastest method without pixel splitting ...other methods may be faster
kwargs["method"] = IntegrationMethod.select_method(dim=1,
split="no",
algo="csr",
impl="opencl",
target_type="gpu")[0]
print(kwargs["method"])
IntegrationMethod(1d int, no split, CSR, OpenCL, NVIDIA CUDA / Quadro K2200)
[8]:
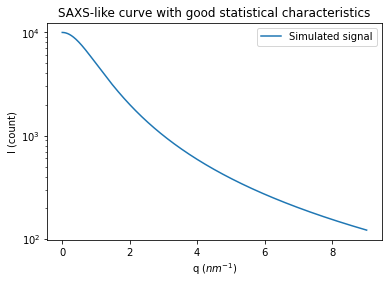
# Generation of a "SAXS-like" curve with the shape of a lorentzian curve
q = numpy.linspace(0, res_flat.radial.max(), npt)
I = I0/(1+q**2)
fig, ax = subplots()
ax.semilogy(q, I, label="Simulated signal")
ax.set_xlabel("q ($nm^{-1}$)")
ax.set_ylabel("I (count)")
ax.set_title("SAXS-like curve with good statistical characteristics")
ax.legend()
pass
[9]:
#Reconstruction of diffusion image:
img_theo = ai.calcfrom1d(q, I, dim1_unit="q_nm^-1",
correctSolidAngle=False,
polarization_factor=None)
fig, ax = subplots()
ax.imshow(img_theo, norm=LogNorm())
ax.set_title("Diffusion image")
pass
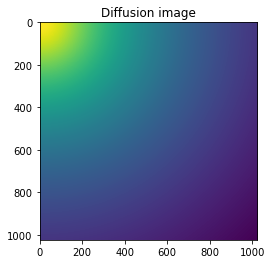
[10]:
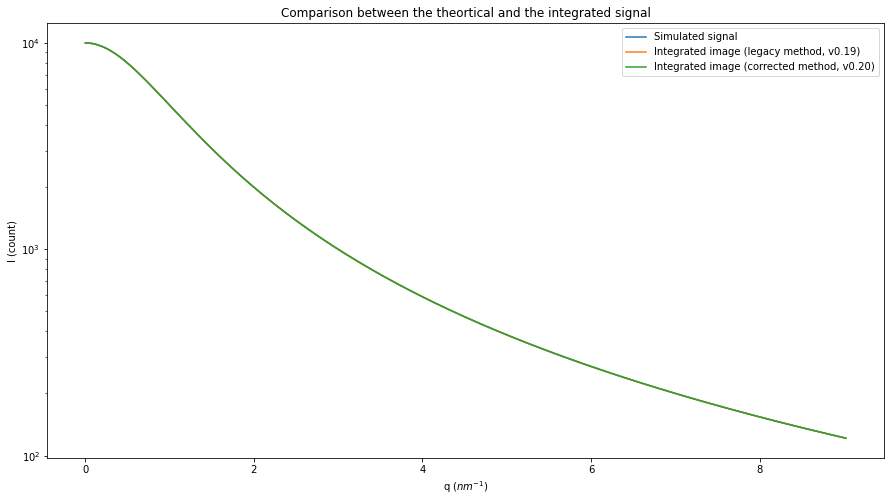
fig, ax = subplots(figsize=(15,8))
ax.semilogy(q, I, label="Simulated signal")
ax.set_xlabel("q ($nm^{-1}$)")
ax.set_ylabel("I (count)")
res_ng = ai.integrate1d_ng(img_theo, **kwargs)
res_legacy = ai.integrate1d_legacy(img_theo, **kwargs)
ax.plot(*res_legacy, label="Integrated image (legacy method, v0.19)")
ax.plot(*res_ng, label="Integrated image (corrected method, v0.20)")
ax.set_title("Comparison between the theortical and the integrated signal")
#Display the error: commented as it makes the graph less readable
#I_bins = I0/(1+res.radial**2)
#ax.plot(res.radial, abs(res.intensity-I_bins), label="error")
ax.legend()
pass
Construction of a synthetic dataset#
We construct now a synthetic dataset of thousand images of this reference image with a statistical distribution which is common for photon-counting detectors (like Pilatus or Eiger): The Poisson distribution. The signal is between 100 and 10000, so every pixel should see photons and there is should be no “rare-events” bias (which sometimes occures in SAXS).
Poisson distribution:#
The Poisson distribution has the peculiarity of having its variance equal to the signal, hence the standard deviation equals to the square root of the signal.
Nota: the generation of the images is slow and takes about 1Gbyte of memory !
[11]:
%%time
if "dataset" not in dir():
dataset = numpy.random.poisson(img_theo, (nimg,) + img_theo.shape)
# else avoid wasting time
print(dataset.nbytes/(1<<20), "MBytes", dataset.shape)
8000.0 MBytes (1000, 1024, 1024)
CPU times: user 48 s, sys: 1.2 s, total: 49.2 s
Wall time: 49.2 s
Validation of the Poisson distribution.#
We have now thousand images of one magapixel. It is interesting to validate if the distribution actually follows the Poisson distribution. For this we will check if the signal and its variance follow a \(\chi^2\) distribution.
For every pair of images I and J we calculate the numerical value of \(\chi ^2\):
The distibution is obtained by calculating the histogram of \(\chi^2\) values for every pair of images, here almost half a milion.
The calculation of the \(\chi^2\) value is likely to be critical in time, so we will shortly investigate 3 implementation: numpy (fail-safe but not that fast), numexp and numba Do not worry if any of the two later method fail: they are faster but provide the same numerical result as numpy.
[12]:
print("Number of paires of images: ", nimg*(nimg-1)//2)
Number of paires of images: 499500
[13]:
#Numpy implementation of Chi^2 measurement for a pair of images. Fail-safe implementation
def chi2_images_np(I, J):
"""Calculate the Chi2 value for a pair of images with poissonnian noise
Numpy implementation"""
return ((I-J)**2/(I+J)).sum()/(I.size - 1)
img0 = dataset[0]
img1 = dataset[1]
print("𝜒² value calculated from numpy on the first pair of images:", chi2_images_np(img0, img1))
%timeit chi2_images_np(img0, img1)
𝜒² value calculated from numpy on the first pair of images: 1.0015036932580994
3.59 ms ± 82.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
[14]:
#Numexp implementation of Chi^2 measurement for a pair of images.
import numexpr
from numexpr import NumExpr
expr = NumExpr("((I-J)**2/(I+J))", signature=[("I", numpy.float64),("J", numpy.float64)])
def chi2_images_ne(I, J):
"""Calculate the Chi2 value for a pair of images with poissonnian noise
NumExpr implementation"""
return expr(I, J).sum()/(I.size-1)
img0 = dataset[0]
img1 = dataset[1]
print("𝜒² value calculated from numexpr on the first pair of images:",chi2_images_ne(img0, img1))
for i in range(6):
j = 1<<i
numexpr.set_num_threads(j)
print(f"Timing when using {j} threads: ")
%timeit -r 3 chi2_images_ne(img0, img1)
#May fail if numexpr is not installed, but gives the same numerical value, just faster
𝜒² value calculated from numexpr on the first pair of images: 1.0015036932580994
Timing when using 1 threads:
4.63 ms ± 30.3 μs per loop (mean ± std. dev. of 3 runs, 100 loops each)
Timing when using 2 threads:
3.02 ms ± 111 μs per loop (mean ± std. dev. of 3 runs, 100 loops each)
Timing when using 4 threads:
1.86 ms ± 19.5 μs per loop (mean ± std. dev. of 3 runs, 1,000 loops each)
Timing when using 8 threads:
1.41 ms ± 33.4 μs per loop (mean ± std. dev. of 3 runs, 1,000 loops each)
Timing when using 16 threads:
1.2 ms ± 18.3 μs per loop (mean ± std. dev. of 3 runs, 1,000 loops each)
Timing when using 32 threads:
1.35 ms ± 18.7 μs per loop (mean ± std. dev. of 3 runs, 1,000 loops each)
[15]:
#Numba implementation of Chi^2 measurement for a pair of images.
from numba import jit, njit, prange
@njit(parallel=True)
def chi2_images_nu(img1, img2):
"""Calculate the Chi2 value for a pair of images with poissonnian noise
Numba implementation"""
I = img1.ravel()
J = img2.ravel()
l = len(I)
#assert len(J) == l
#version optimized for JIT
s = 0.0
for i in prange(len(I)):
a = float(I[i])
b = float(J[i])
s+= (a-b)**2/(a+b)
return s/(l-1)
img0 = dataset[0]
img1 = dataset[1]
print("𝜒² value calculated from numba on the first pair of images:", chi2_images_nu(img0, img1))
%timeit chi2_images_nu(img0, img1)
#May fail if numba is not installed.
# The numerical value, may differ due to reduction algorithm used, should be the fastest.
𝜒² value calculated from numba on the first pair of images: 1.0015036932581176
323 μs ± 4.66 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
[16]:
# Select the prefered algorithm for calculating the numerical value of chi^2 for a pair of images.
#chi2_images = chi2_images_ne
#numexpr.set_num_threads(16)
chi2_images = chi2_images_nu
[17]:
%%time
#Calculate the numerical value for chi2 for every pair of images. This takes a while
c2i = []
for i in range(nimg):
img1 = dataset[i]
for img2 in dataset[:i]:
c2i.append(chi2_images(img1, img2))
c2i = numpy.array(c2i)
CPU times: user 29min 33s, sys: 4min 15s, total: 33min 49s
Wall time: 2min 37s
[18]:
fig, ax = subplots()
h,b,_ = ax.hist(c2i, 100, label="measured distibution")
ax.plot()
size = numpy.prod(shape)
y_sim = chi2_dist.pdf(b*(size-1), size)
y_sim *= h.sum()/y_sim.sum()
ax.plot(b, y_sim, label=r"$\chi^2$ distribution")
ax.set_title("Is the set of images Poissonian?")
ax.legend()
pass
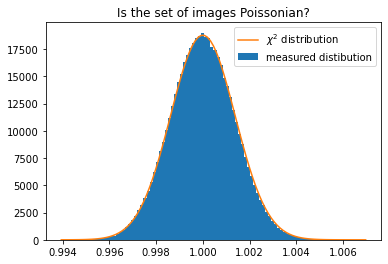
This validates the fact that our set of image is actually a Poissonian distribution around the target image displayed in figure 3.
Integration of images in the SAXS appoximation:#
We can now integrate all images and check wheather all pairs of curves (with their associated error) fit or not the \(\chi^2\) distribution.
It is important to remind that we stay in SAXS approximation, i.e. no solid angle correction or other position-dependent normalization. The pixel splitting is also disabled. So the azimuthal integration is simply:
The number of bins in the curve being much smaller than the number of pixel in the input image, this calculation is less time-critical. So we simply define the same kind of \(\chi^2\) function using numpy.
[19]:
def chi2_curves(res1, res2):
"""Calculate the Chi2 value for a pair of integrated data"""
I = res1.intensity
J = res2.intensity
l = len(I)
assert len(J) == l
sigma_I = res1.sigma
sigma_J = res2.sigma
return ((I-J)**2/(sigma_I**2+sigma_J**2)).sum()/(l-1)
[20]:
%%time
#Perform the azimuthal integration of every single image
integrated = [ai.integrate1d_legacy(data, variance=data, **kwargs)
for data in dataset]
CPU times: user 5.27 s, sys: 13.8 ms, total: 5.29 s
Wall time: 5.28 s
[21]:
#Check if chi^2 calculation is time-critical:
%timeit chi2_curves(integrated[0], integrated[1])
6.4 μs ± 17 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
[22]:
%%time
c2 = []
for i in range(nimg):
res1 = integrated[i]
for res2 in integrated[:i]:
c2.append(chi2_curves(res1, res2))
c2 = numpy.array(c2)
CPU times: user 3.26 s, sys: 709 μs, total: 3.26 s
Wall time: 3.25 s
[23]:
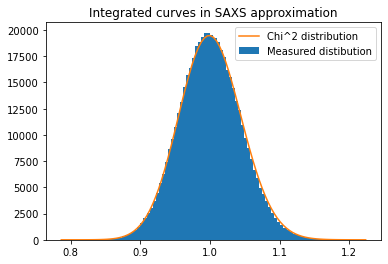
fig, ax = subplots()
h,b,_ = ax.hist(c2, 100, label="Measured distibution")
y_sim = chi2_dist.pdf(b*(npt-1), npt)
y_sim *= h.sum()/y_sim.sum()
ax.plot(b, y_sim, label=r"Chi^2 distribution")
ax.set_title("Integrated curves in SAXS approximation")
ax.legend()
pass
[24]:
low_lim, up_lim = chi2_dist.ppf([0.005, 0.995], nimg) / (nimg - 1)
print(low_lim, up_lim)
print("Expected outliers: ", nimg*(nimg-1)*0.005/2, "got",
(c2<low_lim).sum(),"below and ",(c2>up_lim).sum(), "above")
0.889452976157626 1.1200681344576493
Expected outliers: 2497.5 got 1975 below and 2123 above
Integration of images with solid angle correction/polarization correction#
PyFAI applies by default solid-angle correction which is needed for powder diffraction. On synchrotron sources, the beam is highly polarized and one would like to correct for this effect as well. How does it influence the error propagation ?
If we enable the solid angle normalisation (noted \(\Omega\)) and the polarisation correction (noted \(P\)), this leads us to:
Flatfield correction and any other normalization like pixel efficiency related to sensor thickness should be accounted in the same way.
Nota: The pixel splitting remains disabled.
[25]:
kwargs = {"npt":npt,
"correctSolidAngle": True,
"polarization_factor": 0.9,
"error_model": "poisson",
"safe":False}
kwargs["method"] = IntegrationMethod.select_method(dim=1,
split="no",
algo="csr",
impl="opencl",
target_type="gpu")[-1]
print(kwargs["method"])
# Since we use "safe"=False, we need to reset the integrator manually:
ai.reset()
def plot_distribution(ai, kwargs, nbins=100, integrate=None, ax=None):
ai.reset()
results = []
c2 = []
if integrate is None:
integrate = ai._integrate1d_legacy
for i in range(nimg):
data = dataset[i, :, :]
r = integrate(data, **kwargs)
results.append(r)
for j in results[:i]:
c2.append(chi2_curves(r, j))
c2 = numpy.array(c2)
if ax is None:
fig, ax = subplots()
h,b,_ = ax.hist(c2, nbins, label="Measured histogram")
y_sim = chi2_dist.pdf(b*(npt-1), npt)
y_sim *= h.sum()/y_sim.sum()
ax.plot(b, y_sim, label=r"$\chi^{2}$ distribution")
ax.set_title(f"Integrated curves with {integrate.__name__}")
ax.set_xlabel("$\chi^{2}$ values (histogrammed)")
ax.set_ylabel("Number of occurences")
ax.legend()
return ax
a=plot_distribution(ai, kwargs)
IntegrationMethod(1d int, no split, CSR, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030)
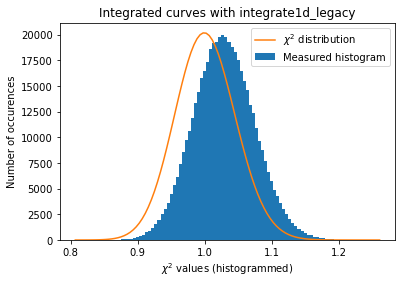
The normalisation of the raw signal distorts the distribution of error, even at a level of a few percent correction ! (Thanks Daniel Franke for the demonstration)
Introducing the new generation of azimuthal integrator … in production since 0.20#
As any normalization introduces some distortion into the error propagation, the error propagation should properly account for this. Alessandro Mirone suggested to treat normalization within azimuthal integration like this :
This is under investigation since begining 2017 silx-kit/pyFAI#520 and is now available in production.
Nota: This is a major issue as almost any commercial detector comes with flatfield correction already applied on raw images; making impossible to properly propagate the error (I am especially thinking at photon counting detectors manufactured by Dectris!). The detector should then provide the actual raw-signal and the flatfield normalization to allow proper signal and error propagation.
Here is a comparison between the legacy integrators and the new generation ones:
[26]:
#The new implementation provides almost the same result as the former one:
ai.reset()
fig, ax = subplots()
data = dataset[0]
ax.set_yscale("log")
jupyter.plot1d(ai.integrate1d_legacy(data, **kwargs), ax=ax, label="version<=0.19")
jupyter.plot1d(ai.integrate1d_ng(data, **kwargs), ax=ax, label="verision>=0.20")
ax.legend()
pass
# If you zoom in enough, you will see the difference !
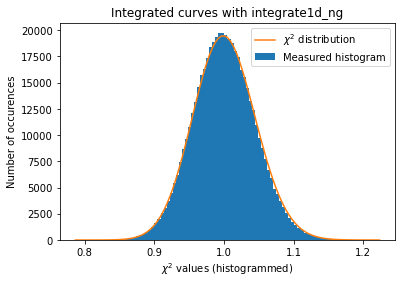
[27]:
#Validation of the error propagation without pixel splitting but with normalization:
a=plot_distribution(ai, kwargs, integrate = ai.integrate1d_ng)
[28]:
#Validation of the error propagation without pixel splitting with azimuthal error assessement
kw_azim = kwargs.copy()
kw_azim["error_model"] = "azimuthal"
kw_azim["correctSolidAngle"] = False
kw_azim["polarization_factor"] = None
a=plot_distribution(ai, kw_azim, integrate = ai.integrate1d_ng)
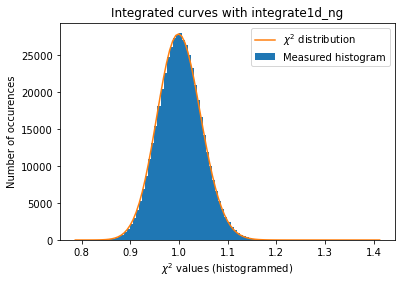
[29]:
#what if we use weights (solid-angle, polarization, ...) together with azimuthal error assessement ?
#Validation of the error propagation without pixel splitting with azimuthal error assessement
kw_azim = kwargs.copy()
kw_azim["error_model"] = "azimuthal"
kw_azim["correctSolidAngle"] = True
kw_azim["polarization_factor"] = 0.95
a=plot_distribution(ai, kw_azim, integrate = ai.integrate1d_ng)
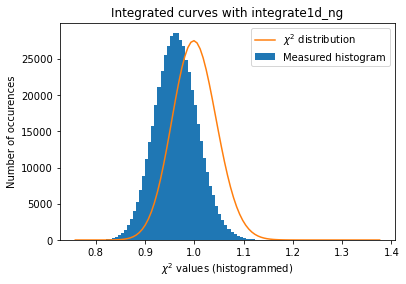
The azimuthal error model is not correct yet … work needs to go on in that direction.
Azimuthal integration with pixel splitting#
Pixels splitting is implemented in pyFAI in calculating the fraction of area every pixel spends in any bin. This is noted \(c^{pix}_{bin}\). The calculation of those coeficient is done with some simple geometry but it is rather tedious, this is why two implementation exists: a simple one which assues pixels boundary are paralle to the radial and azimuthal axes called bbox for bounding box and a more precise one calculating the intersection of polygons (called full. The calculation of
those coefficient is what lasts during the initialization of the integrator as this piece of code is not (yet) parallelized. The total number of (complete) pixel in a bin is then simply the sum of all those coeficients: \(\sum_{pix \in bin} c^{pix}_{bin}\).
The azimuthal integration used to be implemented as (pyFAI <=0.15):
With the associated error propagation (with the error!):
The new generation of integrator in production since version 0.20 (in 1D at least) are implemented like this:
the associated variance propagation should look like this:
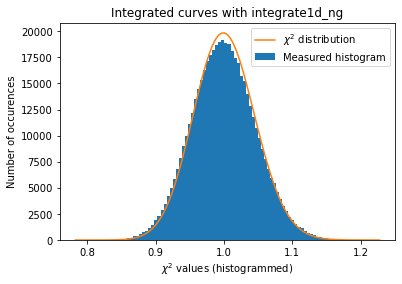
Since we have now tools to validate the error propagation for every single rebinning engine. Let’s see if pixel splitting induces some error, with coarse or fine pixel splitting:
[30]:
#With coarse pixel-splitting, new integrator:
kwargs["method"] = IntegrationMethod.select_method(dim=1,
split="bbox",
algo="csr",
impl="opencl",
target_type="gpu")[-1]
print(kwargs["method"])
a = plot_distribution(ai, kwargs, integrate = ai.integrate1d_ng)
IntegrationMethod(1d int, bbox split, CSR, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030)
[31]:
#With fine pixel-splitting, new integrator:
# so we chose the nosplit_csr_ocl_gpu, other methods may be faster depending on the computer
kwargs["method"] = IntegrationMethod.select_method(dim=1,
split="full",
algo="csr",
impl="opencl",
target_type="gpu")[-1]
print(kwargs["method"])
a = plot_distribution(ai, kwargs, integrate = ai.integrate1d_ng)
IntegrationMethod(1d int, full split, CSR, OpenCL, NVIDIA CUDA / NVIDIA GeForce GT 1030)
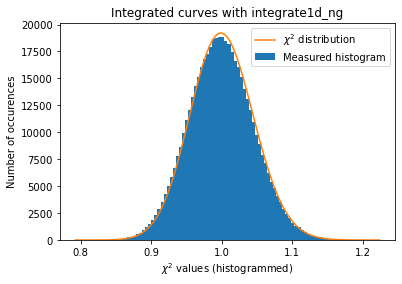
With those modification available, we are now able to estimate the error propagated from one curve and compare it with the “usual” result from pyFAI:
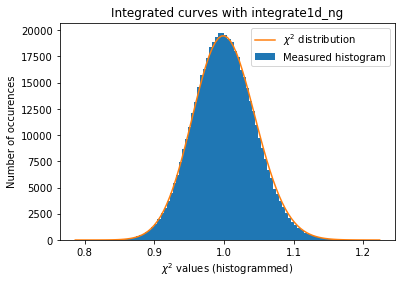
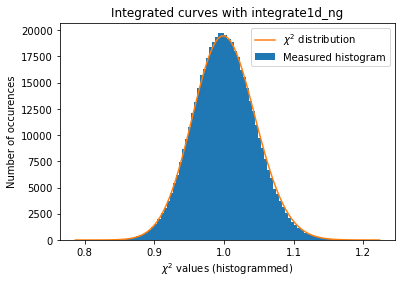
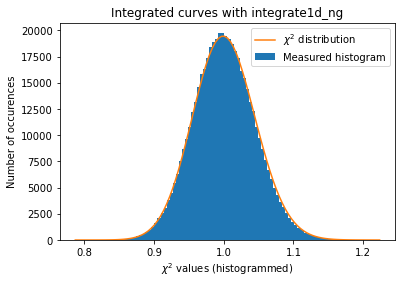
The integrated curves are now following the \(\chi^2\) distribution, which means that the errors provided are in accordance with the data.
[32]:
# Python histogramming without pixels splitting.
kwargs = {"npt":npt,
"method": ("no", "histogram", "python"),
"correctSolidAngle": True,
"polarization_factor": 0.9,
"safe": False,
"error_model": "poisson"}
a = plot_distribution(ai, kwargs, integrate=ai._integrate1d_ng)
[33]:
# Cython histogramming without pixels splitting.
kwargs = {"npt":npt,
"method": ("no", "histogram", "cython"),
"correctSolidAngle": True,
"polarization_factor": 0.9,
"safe": False,
"error_model": "poisson"}
a = plot_distribution(ai, kwargs, integrate=ai._integrate1d_ng)
[34]:
# OpenCL histogramming without pixels splitting.
kwargs = {"npt":npt,
"method": ("no", "histogram", "opencl"),
"correctSolidAngle": True,
"polarization_factor": 0.9,
"safe": False,
"error_model": "poisson"}
a = plot_distribution(ai, kwargs, integrate=ai._integrate1d_ng)
Conclusion#
PyFAI’s historical version (version <=0.16) has been providing proper error propagation ONLY in the case where any normalization (solid angle, flatfield, polarization, …) and pixel splitting was DISABLED. This notebook demonstrates the correctness of the new integrator. Moreover the fact the normalization is performed as part of the integration is a major issue as almost any commercial detector comes with flatfield correction already applied.
[35]:
print(f"Total execution time: {time.perf_counter()-start_time:.3f} s")
Total execution time: 496.328 s