malloc etc.), memory allocation in C++ is handled by
the operators new and delete.
Important differences between malloc and new are:
malloc doesn't `know' what the allocated memory
will be used for. E.g., when memory for ints is allocated, the programmer
must supply the correct expression using a multiplication by
sizeof(int). In contrast, new requires a type to be specified; the
sizeof expression is implicitly handled by the compiler. Using new is
therefore type safe.
malloc is initialized by calloc,
initializing the allocated characters to a configurable initial value. This
is not very useful when objects are available. As operator new knows about
the type of the allocated entity it may (and will) call the constructor of an
allocated class type object. This constructor may be also supplied with
arguments.
NULL-returns. This is not required anymore when new is used. In fact,
new's behavior when confronted with failing memory allocation is
configurable through the use of a new_handler (cf. section
9.2.2).
free and delete:
delete makes sure that when an object is deallocated, its
destructor is automatically called.
The automatic calling of constructors and destructors when objects are created and destroyed has consequences which we shall discuss in this chapter. Many problems encountered during C program development are caused by incorrect memory allocation or memory leaks: memory is not allocated, not freed, not initialized, boundaries are overwritten, etc.. C++ does not `magically' solve these problems, but it does provide us with tools to prevent these kinds of problems.
As a consequence of malloc and friends becoming deprecated
the very frequently used str... functions, like
strdup, that are all malloc based, should be avoided in
C++ programs. Instead, the facilities of the string class and
operators new and delete should be used.
Memory allocation procedures influence the way classes dynamically allocating
their own memory should be designed. Therefore, in this chapter these topics
are discussed in addition to discussions about operators new and
delete. We'll first cover the peculiarities of operators new and
delete, followed by a discussion about:
this pointer, allowing explicit references to the object for
which a member function was called;
new and delete.
Here is a simple example illustrating their use. An int pointer variable
points to memory allocated by operator new. This memory is later released
by operator delete.
int *ip = new int;
delete ip;
Here are some characteristics of operators new and delete:
new and delete are operators and therefore do not
require parentheses, as required for functions like malloc and
free;
new returns a pointer to the kind of memory that's asked for by
its operand (e.g., it returns a pointer to an int);
new uses a type as its operand, which has the important
benefit that the correct amount of memory, given the type of the object to be
allocated, is made available;
new is a type safe operator as it always
returns a pointer to the type that was mentioned as its operand. In addition,
the type of the receiving pointer
must match the type specified with operator new;
new may fail, but this is normally of no concern to the
programmer. In particular, the program does not have to test the success
of the memory allocation, as is required for malloc and
friends. Section 9.2.2 delves into this aspect of new;
delete returns void;
new a matching delete should eventually be
executed, lest a memory leak occurs;
delete can safely operate on a 0-pointer (doing nothing);
delete must only be used to return memory allocated
by new. It should not be used to return memory allocated by
malloc and friends.
malloc and friends are deprecated and should be
avoided.
Operator new can be used to allocate primitive types but also to
allocate objects. When a primitive type
or a struct type without a constructor is allocated the allocated
memory is not guaranteed to be initialized to 0, but an
initialization expression may be provided:
int *v1 = new int; // not guaranteed to be initialized to 0
int *v1 = new int(); // initialized to 0
int *v2 = new int(3); // initialized to 3
int *v3 = new int(3 * *v2); // initialized to 9
When a class-type object is allocated, the arguments of its constructor
(if any) are specified immediately following the type specification in the
new expression and the object is initialized by to the thus specified
constructor. For example, to allocate string objects the following
statements could be used:
string *s1 = new string; // uses the default constructor
string *s2 = new string{}; // same
string *s3 = new string(4, ' '); // initializes to 4 blanks.
In addition to using new to allocate memory for a single entity or an
array of entities (see the next section) there also exists a variant
allocating raw memory:
operator new(sizeInBytes). Raw memory is returned as a void *. Here
new allocates a block of memory for unspecified purpose. Although raw
memory may consist of multiple characters it should not be interpreted as an
array of characters. Since raw memory returned by new is returned as a
void * its return value can be assigned to a void * variable. More
often it is assigned to a char * variable, using a cast. Here is an
example:
char *chPtr = static_cast<char *>(operator new(numberOfBytes));
The use of raw memory is frequently encountered in combination with the placement new operator, discussed in section 9.1.5.
new[] is used to allocate arrays. The generic notation
new[] is used in the C++ Annotations. Actually, the number of elements to be
allocated must be specified between the square brackets and it must, in turn,
be prefixed by the type of the entities that must be allocated. Example:
int *intarr = new int[20]; // allocates 20 ints
string *stringarr = new string[10]; // allocates 10 strings.
Operator new is a different operator than operator new[]. A
consequence of this difference is discussed in the next section
(9.1.2).
Arrays allocated by operator new[] are called
dynamic arrays. They are constructed during the
execution of a program, and their lifetime may exceed the lifetime of the
function in which they were created. Dynamically allocated arrays may last for
as long as the program runs.
When new[] is used to allocate an array of primitive values or an
array of objects, new[] must be specified with a type and an (unsigned)
expression between its square brackets. The type and expression together are
used by the compiler to determine the required size of the block of memory to
make available. When new[] is used the array's elements are stored
consecutively in memory. An array index expression may thereafter be used to
access the array's individual elements: intarr[0] represents the first
int value, immediately followed by intarr[1], and so on until the last
element (intarr[19]).
With non-class types (primitive types, POD
types without constructors) the block of memory returned by operator new[]
is not guaranteed to be initialized to 0. Alternatively, adding () to
the new expression will initialize the block of memory to
zeroes. E.g.,
struct POD
{
int iVal;
double dVal;
};
new POD[5](); // returns a pointer to 5 0-initialized PODs
new double[9](); // returns a pointer to 9 0-initialized doubles
In addition to using new Type[size](), the array's size can also be
inferred by the compiler by specifying comma-separated initialization values
between the parentheses, like new int[](1, 2, 3). This allocates an array
of three ints which are initialized to, respectively, the values 1, 2 and
3. Specifying a larger value between the square brackets is also possible. In
that case the first values are initialized as specified, the remaining values
are initialized to zeroes (or by the objects' default constructors). Instead
of using parentheses curly braces can also be used.
If there are members of the struct POD that are explicitly initialized
in the struct's interface (e.g., int iVal = 12), or if the struct uses
composition, and the composed data member's type defines a default
constructor, then initializations in the struct's interface and
initializations performed by the composed data member's constructor takes
precedence over the 0-initialization. Here is an example:
struct Data
{
int value = 100;
};
struct POD
{
int iVal = 12;
double dVal;
Data data;
};
POD *pp = new POD[5]();
Here, pp points to five POD objects, each having their iVal
data members initialized to 12, their dVal data members initialized to 0,
and their data.value members initialized to 100.
When operator new[] is used to allocate arrays of objects of class
types defining default constructors these constructors are automatically
used. Consequently new string[20] results in a block of 20 initialized
string objects. A non-default constructor cannot be called, but often it
is possible to work around that (as discussed in section 13.8).
The expression between brackets of operator new[] represents the
number of elements of the array to allocate. The C++ standard allows
allocation of 0-sized arrays. The statement
new int[0] is correct C++. However, it is also
pointless and confusing and should be avoided. It is pointless as it doesn't
refer to any element at all, it is confusing as the returned pointer has a
useless non-0 value. A pointer intending to point to an array of values should
be initialized (like any pointer that isn't yet pointing to memory) to 0,
allowing for expressions like if (ptr) ...
Without using operator new[], arrays of variable sizes can also be
constructed as
local arrays. Such arrays are not dynamic arrays and
their lifetimes are restricted to the lifetime of the block in which they were
defined.
Once allocated, all arrays have fixed sizes. There is no
simple way to enlarge or shrink arrays. C++ has no operator
`renew'. Section 9.1.3 illustrates how to
enlarge arrays.
delete[]. It expects a pointer to a block of memory, previously allocated
by operator new[].
When operator delete[]'s operand is a pointer to an array of objects
two actions are performed:
std::string *sp = new std::string[10];
delete[] sp;
No special action is performed if a dynamically allocated array of
primitive typed values is deleted. Following int *it = new int[10] the
statement delete[] it simply returns the memory pointed at by it.
Realize that, as a pointer is a primitive type, deleting a dynamically
allocated array of pointers to objects does not result in the proper
destruction of the objects the array's elements point at. So, the following
example results in a memory leak:
string **sp = new string *[5];
for (size_t idx = 0; idx != 5; ++idx)
sp[idx] = new string;
delete[] sp; // MEMORY LEAK !
In this example the only action performed by delete[] is to return an
area the size of five pointers to strings to the common pool.
Here's how the destruction in such cases should be performed:
delete for each of the array's elements;
for (size_t idx = 0; idx != 5; ++idx)
delete sp[idx];
delete[] sp;
One of the consequences is of course that by the time the memory is going to be returned not only the pointer must be available but also the number of elements it contains. This can easily be accomplished by storing pointer and number of elements in a simple class and then using an object of that class.
Operator delete[] is a different operator than operator
delete. The rule of thumb is: if new[] was used, also use
delete[].
renew operator. The basic steps to take when enlarging an array are the
following:
#include <string>
using namespace std;
string *enlarge(string *old, size_t oldsize, size_t newsize)
{
string *tmp = new string[newsize]; // allocate larger array
for (size_t idx = 0; idx != oldsize; ++idx)
tmp[idx] = old[idx]; // copy old to tmp
delete[] old; // delete the old array
return tmp; // return new array
}
int main()
{
string *arr = new string[4]; // initially: array of 4 strings
arr = enlarge(arr, 4, 6); // enlarge arr to 6 elements.
}
The procedure to enlarge shown in the example also has several drawbacks.
newsize constructors to be called;
oldsize of them
are immediately reassigned to the corresponding values in the original array;
new allocates the memory for an object and
subsequently initializes that object by calling one of its
constructors. Likewise, operator delete calls an object's destructor and
subsequently returns the memory allocated by operator new to the common
pool.
In the next section we'll encounter another use of new, allowing us to
initialize objects in so-called raw memory: memory merely consisting of
bytes that have been made available by either static or dynamic allocation.
Raw memory is made available by
operator new(sizeInBytes) and also by operator
new[](sizeInBytes). The returned memory should not be interpreted as an array
of any kind but just a series of memory locations that were dynamically made
available. No initialization whatsoever is performed by these variants of
new.
Both variants return void *s so (static) casts are required to use the
return values as memory of some type.
Here are two examples:
// room for 5 ints:
int *ip = static_cast<int *>(operator new(5 * sizeof(int)));
// same as the previous example:
int *ip2 = static_cast<int *>(operator new[](5 * sizeof(int)));
// room for 5 strings:
string *sp = static_cast<string *>(operator new(5 * sizeof(string)));
As operator new has no concept of data types the size of the intended
data type must be specified when allocating raw memory for a certain number of
objects of an intended type. The use of operator new therefore somewhat
resembles the use of malloc.
The counterpart of operator new is operator delete. Operator
delete (or, equivalently, operator delete[]), expects a void * (so a
pointer to any type can be passed to it). The pointer is interpreted as a
pointer to raw memory which is returned to the common pool without any further
action. In particular, no destructors are called by operator delete. The
use of operator delete therefore resembles the use of free. To return
the memory pointed at by the abovementioned variables ip and sp
operator delete should be used:
// delete raw memory allocated by operator new
operator delete(ip);
operator delete[](ip2);
operator delete(sp);
new is called the placement new
operator. Before using placement new the <memory>
header file must be included.
Placement new is passed an existing block of memory into which new
initializes an object or value. The block of memory should be large enough to
contain the object, but apart from that there are no further requirements. It
is easy to determine how much memory is used by an entity (object or variable)
of type Type: the
sizeof operator returns the number of bytes used by an Type entity.
Entities may of course dynamically allocate memory for their own use.
Dynamically allocated memory, however, is not part of the entity's memory
`footprint' but it is always made available externally to the entity
itself. This is why sizeof returns the same value when applied to
different string objects that return different length and capacity values.
The placement new operator uses the following syntax (using Type to
indicate the used data type):
Type *new(void *memory) Type{ arguments };
Here, memory is a block of memory of at least sizeof(Type) bytes
and Type(arguments) is any constructor of the class Type.
The placement new operator is useful in situations where classes set
aside memory to be used later. This is used, e.g., by std::string to
change its capacity. Calling string::reserve may enlarge that capacity
without making memory beyond the string's length immediately available to the
string object's users. But the object itself may use its additional
memory. E.g, when information is added to a string object it can draw
memory from its capacity rather than performing a reallocation for each single
character that is added to its content.
Let's apply that philosophy to a class Strings storing std::string
objects. The class defines a string *d_memory accessing the memory holding
its d_size string objects as well as d_capacity - d_size reserved
memory. Assuming that a default constructor initializes d_capacity to 1,
doubling d_capacity whenever an additional string must be stored, the
class must support the following essential operations:
reserve) has been consumed;
string object
Strings object ceases to exist.
void Strings::reserve is called when the current
capacity must be enlarged to d_capacity. It operates as follows:
First new, raw, memory is allocated (line 1). This memory is in no way
initialized with strings. Then the available strings in the old memory are
copied into the newly allocated raw memory using placement new (line 2). Next,
the old memory is deleted (line 3).
void Strings::reserve()
{
using std::string;
string *newMemory = static_cast<string *>( // 1
operator new(d_capacity * sizeof(string)));
for (size_t idx = 0; idx != d_size; ++idx) // 2
new (newMemory + idx) string{ d_memory[idx] };
destroy(); // 3
d_memory = newMemory;
}
The member append adds another string object to a Strings
object. A (public) member reserve(request) (enlarging d_capacity if
necessary and if enlarged calling reserve()) ensures that the String
object's capacity is sufficient. Then placement new is used to install the
latest string into the raw memory's appropriate location:
void Strings::append(std::string const &next)
{
reserve(d_size + 1);
new (d_memory + d_size) std::string{ next };
++d_size;
}
At the end of the String object's lifetime, and during enlarging
operations all currently used dynamically allocated memory must be
returned. This is made the responsibility of the member destroy, which is
called by the class's destructor and by reserve(). More about the
destructor itself in the next section, but the
implementation of the support member destroy is discussed below.
With placement new an interesting situation is encountered. Objects,
possibly themselves allocating memory, are installed in memory that may or may
not have been allocated dynamically, but that is usually not completely filled
with such objects. So a simple delete[] can't be used. On the other hand,
a delete for each of the objects that are available can't be used
either, since those delete operations would also try to delete the memory
of the objects themselves, which wasn't dynamically allocated.
This peculiar situation is solved in a peculiar way, only encountered in
cases where placement new is used: memory allocated by objects initialized
using placement new is returned by
explicitly calling the object's destructor. The destructor is
declared as a member having as its name the class name preceded by a tilde,
not using any arguments. So, std::string's destructor is named
~string. An object's destructor only returns memory allocated by the
object itself and, despite of its name, does not destroy its object. Any
memory allocated by the strings stored in our class Strings is
therefore properly destroyed by explicitly calling their
destructors. Following this d_memory is back to its initial status: it
again points to raw memory. This raw memory is then returned to the common
pool by operator delete:
void Strings::destroy()
{
for (std::string *sp = d_memory + d_size; sp-- != d_memory; )
sp->~string();
operator delete(d_memory);
}
So far, so good. All is well as long as we're using only one object. What
about allocating an array of objects? Initialization is performed as usual.
But as with delete, delete[] cannot be called when the buffer was
allocated statically. Instead, when multiple objects were initialized using
placement new in combination with a statically allocated
buffer all the objects' destructors must be called explicitly, as in the
following example:
using std::string;
char buffer[3 * sizeof(string)];
string *sp = new(buffer) string [3];
for (size_t idx = 0; idx < 3; ++idx)
sp[idx].~string();
Several standard template library functions are available for handling unitialized (raw) memory. See section 19.1.58 for a description.
exit call, only the destructors of
already initialized global objects are called. In that situation destructors
of objects defined locally by functions are also not called. This is
one (good) reason for avoiding exit in C++ programs.
Destructors obey the following syntactical requirements:
class Strings
{
public:
Strings();
~Strings(); // the destructor
};
By convention the constructors are declared first. The destructor is declared next, to be followed by other member functions.
A destructor's main task is to ensure that
memory allocated by an object is properly returned when the object ceases to
exist. Consider the following interface of the class Strings:
class Strings
{
std::string *d_string;
size_t d_size;
public:
Strings();
Strings(char const *const *cStrings, size_t n);
~Strings();
std::string const &at(size_t idx) const;
size_t size() const;
};
The constructor's task is to initialize the data fields of the object. E.g, its constructors are defined as follows:
Strings::Strings()
:
d_string(0),
d_size(0)
{}
Strings::Strings(char const *const *cStrings, size_t size)
:
d_string(new string[size]),
d_size(size)
{
for (size_t idx = 0; idx != size; ++idx)
d_string[idx] = cStrings[idx];
}
As objects of the class Strings allocate memory a destructor is
clearly required. Destructors may or may not be called automatically, but note
that destructors are only called (or, in the case of dynamically allocated
objects: should only be called) for fully constructed objects.
C++ considers objects `fully constructed' once at least one of its constructors could normally complete. It used to be the constructor, but as C++ supports constructor delegation, multiple constructors can be activated for a single object; hence `at least one constructor'. The remaining rules apply to fully constructed objects;
delete using the object's address as its operand;
delete[] using the address of the array's first element as its
operand;
new is
activated by explicitly calling the object's destructor.
Strings's
destructor would therefore be to delete the memory to which d_string
points. Its implementation is:
Strings::~Strings()
{
delete[] d_string;
}
The next example shows Strings at work. In process
a Strings store is created, and its data are displayed. It returns a
dynamically allocated Strings object to main. A
Strings * receives the address of the allocated object and deletes the
object again. Another Strings object is then created in a block of
memory made available locally in main, and an
explicit call to ~Strings is required
to return the memory allocated by that object. In the example only once a
Strings object is automatically destroyed: the local Strings
object defined by process. The other two Strings objects require
explicit actions to prevent memory leaks.
#include "strings.h"
#include <iostream>
using namespace std;;
void display(Strings const &store)
{
for (size_t idx = 0; idx != store.size(); ++idx)
cout << store.at(idx) << '\n';
}
Strings *process(char *argv[], size_t argc)
{
Strings store{ argv, argc };
display(store);
return new Strings{ argv, argc };
}
int main(int argc, char *argv[])
{
Strings *sp = process(argv, argc);
delete sp;
char buffer[sizeof(Strings)];
sp = new (buffer) Strings{ argv, static_cast<size_t>(argc) };
sp->~Strings();
}
new and delete are used when an object or variable is
allocated. One of the advantages of the operators new and
delete over functions like malloc and free is that new and
delete call the corresponding object constructors and destructors.
The allocation of an object by operator new is a two-step
process. First the memory for the object itself is allocated. Then its
constructor is called, initializing the object. Analogously to the
construction of an object, the destruction is also a two-step process: first,
the destructor of the class is called deleting the memory controlled by the
object. Then the memory used by the object itself is freed.
Dynamically allocated arrays of objects can also be handled by new and
delete. When allocating an array of objects using operator new the
default constructor is called for each object in the array. In cases like this
operator delete[] must be used to ensure that the destructor is called for
each of the objects in array.
However, the addresses returned by new Type and new Type[size]
are of identical types, in both cases a Type *. Consequently it cannot be
determined by the type of the pointer whether a pointer to dynamically
allocated memory points to a single entity or to an array of entities.
What happens if delete rather than delete[] is used? Consider the
following situation, in which the destructor ~Strings is modified so that
it tells us that it is called. In a main function an array of two
Strings objects is allocated using new, to be deleted by delete[].
Next, the same actions are repeated, albeit that the delete operator is
called without []:
#include <iostream>
#include "strings.h"
using namespace std;
Strings::~Strings()
{
cout << "Strings destructor called" << '\n';
}
int main()
{
Strings *a = new Strings[2];
cout << "Destruction with []'s" << '\n';
delete[] a;
a = new Strings[2];
cout << "Destruction without []'s" << '\n';
delete a;
}
/*
Generated output:
Destruction with []'s
Strings destructor called
Strings destructor called
Destruction without []'s
Strings destructor called
*/
From the generated output, we see that the destructors of the individual
Strings objects are called when delete[] is used, while only the
first object's destructor is called if the [] is omitted.
Conversely, if delete[] is called in a situation where delete
should have been called the results are unpredictable, and the program will
most likely crash. This problematic behavior is caused by the way the run-time
system stores information about the size of the allocated array (usually right
before the array's first element). If a single object is allocated the
array-specific information is not available, but it is nevertheless assumed
present by delete[]. Thus this latter operator encounters bogus values in
the memory locations just before the array's first element. It then dutifully
interprets the value it encounters there as size information, usually causing
the program to fail.
If no destructor is defined, a trivial destructor is defined by the compiler. The trivial destructor ensures that the destructors of composed objects (as well as the destructors of base classes if a class is a derived class, cf. chapter 13) are called. This has serious implications: objects allocating memory create memory leaks unless precautionary measures are taken (by defining an appropriate destructor). Consider the following program:
#include <iostream>
#include "strings.h"
using namespace std;
Strings::~Strings()
{
cout << "Strings destructor called" << '\n';
}
int main()
{
Strings **ptr = new Strings* [2];
ptr[0] = new Strings[2];
ptr[1] = new Strings[2];
delete[] ptr;
}
This program produces no output at all. Why is this? The variable ptr
is defined as a pointer to a pointer. The dynamically allocated array
therefore consists of pointer variables and pointers are of a primitive type.
No destructors exist for primitive typed variables. Consequently only the
array itself is returned, and no Strings destructor is called.
Of course, we don't want this, but require the Strings objects
pointed to by the elements of ptr to be deleted too. In this case we have
two options:
ptr array,
calling delete for each of the array's elements. This procedure was
demonstrated in the previous section.
Strings). Rather than using a pointer to a
pointer to Strings objects a pointer to an array of wrapper-class
objects is used. As a result delete[] ptr calls the destructor of each of
the wrapper class objects, in turn calling the Strings destructor for
their d_strings members. Example:
#include <iostream>
using namespace std;
class Strings // partially implemented
{
public:
~Strings();
};
inline Strings::~Strings()
{
cout << "destructor called\n";
}
class Wrapper
{
Strings *d_strings;
public:
Wrapper();
~Wrapper();
};
inline Wrapper::Wrapper()
:
d_strings(new Strings{})
{}
inline Wrapper::~Wrapper()
{
delete d_strings;
}
int main()
{
auto ptr = new Strings *[4];
// ... code assigning `new Strings' to ptr's elements
delete[] ptr; // memory leak: ~Strings() not called
cout << "===========\n";
delete[] new Wrapper[4]; // OK: 4 x destructor called
}
/*
Generated output:
===========
destructor called
destructor called
destructor called
destructor called
*/
new. Operator new's default behavior may
be modified in various ways. One way to modify its behavior is to redefine the
function that's called when memory allocation fails. Such a function
must comply with the following requirements:
void.
A redefined error function might, e.g., print a message and terminate
the program. The user-written error function becomes part of the allocation
system through the function set_new_handler.
Such an error function is illustrated below ( This implementation applies to the GNU C/C++ requirements. Actually using the program given in the next example is not advised, as it probably enormously slows down your computer due to the resulting use of the operating system's swap area.):
#include <iostream>
#include <string>
using namespace std;
void outOfMemory()
{
cout << "Memory exhausted. Program terminates." << '\n';
exit(1);
}
int main()
{
long allocated = 0;
set_new_handler(outOfMemory); // install error function
while (true) // eat up all memory
{
new int [100000]();
allocated += 100000 * sizeof(int);
cout << "Allocated " << allocated << " bytes\n";
}
}
Once the new error function has been installed it is automatically invoked
when memory allocation fails, and the program is terminated. Memory
allocation may fail in indirectly called code as well, e.g., when constructing
or using streams or when strings are duplicated by low-level functions.
So far for the theory. On some systems the `out of memory' condition may actually never be reached, as the operating system may interfere before the run-time support system gets a chance to stop the program.
The traditional memory allocation functions (like strdup, malloc,
realloc etc.) do not trigger the new handler when memory allocation
fails and should be avoided in C++ programs.
Person:
class Person
{
char *d_name;
char *d_address;
char *d_phone;
public:
Person();
Person(char const *name, char const *addr, char const *phone);
~Person();
private:
char *strdupnew(char const *src); // returns a copy of src.
};
// strdupnew is easily implemented, here is its inline implementation:
inline char *Person::strdupnew(char const *src)
{
return strcpy(new char [strlen(src) + 1], src);
}
Person's data members are initialized to zeroes or to copies of the
NTBSs passed to Person's constructor, using some variant of
strdup. The allocated memory is eventually returned by Person's
destructor.
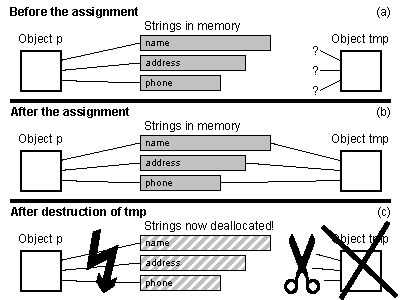
Now consider the consequences of using Person objects in the following
example:
void tmpPerson(Person const &person)
{
Person tmp;
tmp = person;
}
Here's what happens when tmpPerson is called:
Person as its parameter person.
tmp, whose data members are initialized
to zeroes.
person is copied to tmp:
sizeof(Person) number of bytes are copied from person to tmp.
person are pointers, pointing to allocated memory. After the
assignment this memory is addressed by two objects: person and
tmp.
tmpPerson terminates: tmp is
destroyed. The destructor of the class Person releases the memory pointed
to by the fields d_name, d_address and d_phone: unfortunately,
this memory is also pointed at by person....
Having executed tmpPerson, the object referenced by person now
contains pointers to deleted memory.
This is undoubtedly not a desired effect of using a function like
tmpPerson. The deleted memory is likely to be reused by subsequent
allocations. The pointer members of person have effectively become
wild pointers, as they don't point to allocated
memory anymore. In general it can be concluded that
Person object to another, is
not to copy the content of the object bytewise. A better way is to
make an equivalent object. One having its own allocated memory containing
copies of the original strings.
The way to assign a Person object to another is
illustrated in Figure 6.
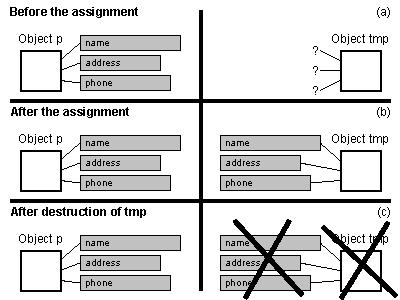
Person object to another. One way
would be to define a special member function to handle the assignment. The
purpose of this member function would be to create a copy of an object having
its own name, address and phone strings. Such a member function
could be:
void Person::assign(Person const &other)
{
// delete our own previously used memory
delete[] d_name;
delete[] d_address;
delete[] d_phone;
// copy the other Person's data
d_name = strdupnew(other.d_name);
d_address = strdupnew(other.d_address);
d_phone = strdupnew(other.d_phone);
}
Using assign we could rewrite the offending function tmpPerson:
void tmpPerson(Person const &person)
{
Person tmp;
// tmp (having its own memory) holds a copy of person
tmp.assign(person);
// now it doesn't matter that tmp is destroyed..
}
This solution is valid, although it only tackles a symptom. It requires the programmer to use a specific member function instead of the assignment operator. The original problem (assignment produces wild pointers) is still not solved. Since it is hard to `strictly adhere to a rule' a way to solve the original problem is of course preferred.
Fortunately a solution exists using operator overloading: the
possibility C++ offers to redefine the actions of an operator in a given
context. Operator overloading was briefly mentioned earlier, when the
operators << and >> were redefined to be used with streams (like
cin, cout and cerr), see section 3.1.4.
Overloading the assignment operator is probably the most common form of operator overloading in C++. A word of warning is appropriate, though. The fact that C++ allows operator overloading does not mean that this feature should indiscriminately be used. Here's what you should keep in mind:
Person.
std::string: assigning one string object to another provides the
destination string with a copy of the content of the source string. No
surprises here.
ints do. The way operators behave when applied to ints is what is
expected, all other implementations probably cause surprises and confusion.
Therefore, overloading the insertion (<<) and extraction (>>)
operators in the context of streams is probably ill-chosen: the stream
operations have nothing in common with bitwise shift operations.
To overload the assignment operator =, a member operator=(Class const
&rhs) is added to the class interface. Note that the function name consists
of two parts: the keyword operator, followed by the operator itself. When
we augment a class interface with a member function operator=, then that
operator is redefined for the class, which prevents the default operator
from being used. In the previous section the function
assign was provided to solve the problems resulting from using the
default assignment operator. Rather than using an ordinary member
function C++ commonly uses a dedicated operator generalizing the
operator's default behavior to the class in which it is defined.
The assign member mentioned before may be redefined as follows (the member
operator= presented below is a first, rather unsophisticated, version of
the overloaded assignment operator. It will shortly be improved):
class Person
{
public: // extension of the class Person
// earlier members are assumed.
void operator=(Person const &other);
};
Its implementation could be
void Person::operator=(Person const &other)
{
delete[] d_name; // delete old data
delete[] d_address;
delete[] d_phone;
d_name = strdupnew(other.d_name); // duplicate other's data
d_address = strdupnew(other.d_address);
d_phone = strdupnew(other.d_phone);
}
This member's actions are similar to those of the previously mentioned
member assign, but this member is automatically called when the assignment
operator = is used. Actually there are two ways to
call overloaded operators as shown in the next example:
void tmpPerson(Person const &person)
{
Person tmp;
tmp = person;
tmp.operator=(person); // the same thing
}
Overloaded operators are seldom called explicitly, but explicit calls must be used (rather than using the plain operator syntax) when you explicitly want to call the overloaded operator from a pointer to an object (it is also possible to dereference the pointer first and then use the plain operator syntax, see the next example):
void tmpPerson(Person const &person)
{
Person *tmp = new Person;
tmp->operator=(person);
*tmp = person; // yes, also possible...
delete tmp;
}
this, to reach this substrate.
The this keyword is a pointer variable that always contains the
address
of the object for which the member
function was called. The this pointer is implicitly declared by each
member function (whether public, protected, or private). The this
pointer is a constant pointer to an object of the member function's
class. For example, the members of the class Person implicitly declare:
extern Person *const this;
A member function like Person::name could be implemented in two ways:
with or without using the this pointer:
char const *Person::name() const // implicitly using `this'
{
return d_name;
}
char const *Person::name() const // explicitly using `this'
{
return this->d_name;
}
The this pointer is seldom explicitly used, but situations do exist
where the this pointer is actually required (cf. chapter
16).
a = b = c;
the expression b = c is evaluated first, and its result in turn is
assigned to a.
The implementation of the overloaded assignment operator we've encountered
thus far does not permit such constructions, as it returns void.
This imperfection can easily be remedied using the this pointer. The
overloaded assignment operator expects a reference to an object of its
class. It can also return a reference to an object of its class. This
reference can then be used as an argument in sequential assignments.
The overloaded assignment operator commonly returns a reference to the
current object (i.e., *this). The next version of the overloaded
assignment operator for the class Person thus becomes:
Person &Person::operator=(Person const &other)
{
delete[] d_address;
delete[] d_name;
delete[] d_phone;
d_address = strdupnew(other.d_address);
d_name = strdupnew(other.d_name);
d_phone = strdupnew(other.d_phone);
// return current object as a reference
return *this;
}
Overloaded operators may themselves be overloaded. Consider the string
class, having overloaded assignment operators operator=(std::string const
&rhs), operator=(char const *rhs), and several more overloaded
versions. These additional overloaded versions are there to handle different
situations which are, as usual, recognized by their argument types. These
overloaded versions all follow the same mold: when necessary dynamically
allocated memory controlled by the object is deleted; new values are assigned
using the overloaded operator's parameter values and *this is returned.
Strings, introduced in section 9.2,
once again. As it contains several primitive type data members as well as a
pointer to dynamically allocated memory it needs a constructor, a destructor,
and an overloaded assignment operator. In fact the class offers two
constructors: in addition to the default constructor it offers a constructor
expecting a char const *const * and a size_t.
Now consider the following code fragment. The statement references are discussed following the example:
int main(int argc, char **argv)
{
Strings s1(argv, argc); // (1)
Strings s2; // (2)
Strings s3(s1); // (3)
s2 = s1; // (4)
}
s1 is initialized using main's parameters: Strings's second
constructor is used.
Strings's default constructor is used, initializing
an empty Strings object.
Strings object is created, using a
constructor accepting an existing Strings object. This form of
initializations has not yet been discussed. It is called a
copy construction and the constructor performing the
initialization is called the copy constructor. Copy constructions are also
encountered in the following form:
Strings s3 = s1;
This is a construction and therefore an initialization. It is not an assignment as an assignment needs a left-hand operand that has already been defined. C++ allows the assignment syntax to be used for constructors having only one parameter. It is somewhat deprecated, though.
The copy constructor encountered here is new. It does not result in a compilation error even though it hasn't been declared in the class interface. This takes us to the following rule:
A copy constructor is (almost) always available, even if it isn't declared in the class's interface.The reason for the `(almost)' is given in section 9.7.1.
The copy constructor made available by the compiler is also called the
trivial copy constructor. Its use can easily be suppressed (using the =
delete idiom). The trivial copy constructor performs a byte-wise copy
operation of the existing object's primitive data to the newly created object,
calls copy constructors to intialize the object's class data members from
their counterparts in the existing object and, when inheritance is used, calls
the copy constructors of the base class(es) to initialize the new object's
base classes.
Consequently, in the above example the trivial copy constructor is
used. As it performs a byte-by-byte copy operation of the object's
primitive type data members that is exactly what happens at statement 3.
By the time s3 ceases to exist its destructor deletes its array of
strings. Unfortunately d_string is of a primitive data type and so it also
deletes s1's data. Once again we encounter wild pointers as a result of an
object going out of scope.
The remedy is easy: instead of using the trivial copy constructor a copy constructor must explicitly be added to the class's interface and its definition must prevent the wild pointers, comparably to the way this was realized in the overloaded assignment operator. An object's dynamically allocated memory is duplicated, so that it contains its own allocated data. But note that if a class also reserves extra (raw) memory, i.e., if it supports extra memory capacity, then that unused extra capacity is not made available in the copy-constructed object.
Copy construction can be used to shed excess
capacity. Copy constructors do not have to shed excess capacity. E.g.,
when copy-constructing std::string objects the destination object defines
the same capacity as the source object. The copy constructor is simpler than
the overloaded assignment operator in that it doesn't have to delete
previously allocated memory. Since the object is going to be created no memory
has already been allocated.
Strings's copy constructor can be implemented as follows:
Strings::Strings(Strings const &other)
:
d_string(new string[other.d_size]),
d_size(other.d_size)
{
for (size_t idx = 0; idx != d_size; ++idx)
d_string[idx] = other.d_string[idx];
}
The copy constructor is always called when an object is initialized using another object of its class. Apart from the plain copy construction that we encountered thus far, here are other situations where the copy constructor is used:
void process(Strings store) // no pointer, no reference
{
store.at(3) = "modified"; // doesn't modify `outer'
}
int main(int argc, char **argv)
{
Strings outer(argv, argc);
process(outer);
}
Strings copy(Strings const &store)
{
return store;
}
store is used to initialize copy's return value. The returned
Strings object is a temporary, anonymous object that may be
immediately used by code calling copy but no assumptions can be made about
its lifetime thereafter.
As we've seen in our discussion of the destructor (section 9.2) the destructor can explicitly be called, but that doesn't hold true for the (copy) constructor. But let's briefly summarize what an overloaded assignment operator is supposed to do:
Strings &operator=(Strings const &other)
{
Strings tmp(other);
// more to follow
return *this;
}
You may think the optimization operator=(Strings tmp) is attractive,
but let's postpone that for a little while (at least until section 9.7).
Now that we've done the copying part, what about the deleting part? And
isn't there another slight problem as well? After all we copied all right, but
not into our intended (current, *this) object.
At this point it's time to introduce swapping. Swapping two variables
means that the two variables exchange their values. We'll discuss swapping in
detail in the next section, but let's for now assume that we've added a member
swap(Strings &other) to our class Strings. This allows us to
complete String's operator= implementation:
Strings &operator=(Strings const &other)
{
Strings tmp(other);
swap(tmp);
return *this;
}
This implementation of operator= is generic: it can be applied to
every class whose objects are swappable. How does it work?
other object is used to initialize a
local tmp object. This takes care of the copying part of the assignment
operator;
swap ensures that the current object receives its new
values (with tmp receiving the current object's original values);
operator= terminates its local tmp object ceases to
exist and its destructor is called. As it by now contains the data previously
owned by the current object, the current object's original data are now
destroyed, effectively completing the destruction part of the assignment
operation.
std::string) offer swap members allowing us to
swap two of their objects. The Standard Template Library (STL, cf. chapter
18) offers various functions related to swapping. There is even a
swap generic algorithm (cf. section 19.1.55), which is commonly
implemented using the assignment operator. When implementing a swap member
for our class Strings it could be used, provided that all of String's
data members can be swapped. As this is true (why this is true is
discussed shortly) we can augment class Strings with a swap member:
void Strings::swap(Strings &other)
{
std::swap(d_string, other.d_string);
std::swap(d_size, other.d_size);
}
Having added this member to Strings the copy-and-swap implementation
of String::operator= can now be used.
When two variables (e.g., double one and double two) are swapped,
each one holds the other one's value after the swap. So, if one == 12.50
and two == -3.14 then after swap(one, two) one == -3.14 and two ==
12.50.
Variables of primitive data types (pointers and the built-in types) can be
swapped, class-type objects can be swapped if their classes offer a swap
member.
So should we provide our classes with a swap member, and if so, how should it be implemented?
The above example (Strings::swap) shows the standard way to implement
a swap member: each of its data members are swapped in turn. But there are
situations where a class cannot implement a swap member this way, even if the
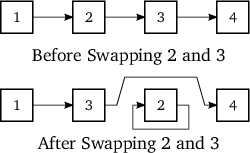
class only defines data members of primitive data types. Consider the
situation depicted in figure 7.
In this figure there are four objects, each object has a pointer pointing to the next object. The basic organization of such a class looks like this:
class List
{
List *d_next;
...
};
Initially four objects have their d_next pointer set to the next
object: 1 to 2, 2 to 3, 3 to 4. This is shown in the upper half of the
figure. At the bottom half it is shown what happens if objects 2 and 3 are
swapped: 3's d_next point is now at object 2, which still points to 4; 2's
d_next pointer points to 3's address, but 2's d_next is now at object
3, which is therefore pointing to itself. Bad news!
Another situation where swapping of objects goes wrong happens with classes having data members pointing or referring to data members of the same object. Such a situation is shown in figure 8.
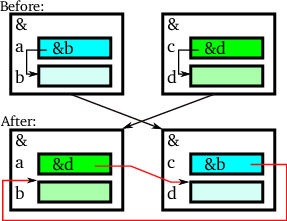
Here, objects have two data members, as in the following class setup:
class SelfRef
{
size_t *d_ownPtr; // initialized to &d_data
size_t d_data;
};
The top-half of figure 8 shows two objects; their upper data members pointing to their lower data members. But if these objects are swapped then the situation shown in the figure's bottom half is encountered. Here the values at addresses a and c are swapped, and so, rather than pointing to their bottom data members they suddenly point to other object's data members. Again: bad news.
The common cause of these failing swapping operations is easily recognized: simple swapping operations must be avoided when data members point or refer to data that is involved in the swapping. If, in figure 8 the a and c data members would point to information outside of the two objects (e.g., if they would point to dynamically allocated memory) then the simple swapping would succeed.
However, the difficulty encountered with swapping SelfRef objects does not
imply that two SelfRef objects cannot be swapped; it only means that we
must be careful when designing swap members. Here is an implementation of
SelfRef::swap:
void SelfRef::swap(SelfRef &other)
{
swap(d_data, other.d_data);
}
In this implementation swapping leaves the self-referential data member
as-is, and merely swaps the remaining data. A similar swap member could be
designed for the linked list shown in figure 7.
new objects can be constructed in blocks
of memory of sizeof(Class) bytes large. And so, two objects of the same
class each occupy sizeof(Class) bytes.
If objects of our class can be swapped, and if our class's data members do not refer to data actually involved in the swapping operation then a very fast swapping method that is based on the fact that we know how large our objects are can be implemented.
In this fast-swap method we merely swap the content of the sizeof(Class)
bytes. This procedure may be applied to classes whose objects may be swapped
using a member-by-member swapping operation and can (in practice, although
this probably overstretches the allowed operations as described by the
C++ ANSI/ISO standard) also be used in classes having reference data
members. It simply defines a buffer of sizeof(Class) bytes and performs a
circular memcpy operation. Here is its implementation for a hypothetical
class Class. It results in very fast swapping:
#include <cstring>
void Class::swap(Class &other)
{
char buffer[sizeof(Class)];
memcpy(buffer, &other, sizeof(Class));
memcpy(static_cast<void *>(&other), this, sizeof(Class));
memcpy(static_cast<void *>(this), buffer, sizeof(Class));
}
The static_cast for memcpy's destination address is used to prevent a
compiler complaint: since Class is a class-type, the compiler (rightly)
warns against bluntly copying bytes. But using memcpy is fine if you're
Class's developer and know what you're doing.
Here is a simple example of a class defining a reference data member and
offering a swap member implemented like the one above. The reference data
members are initialized to external streams. After running the program one
contains two hello to 1 lines, two contains two hello to 2 lines
(for brevity all members of Reference are defined inline):
#include <fstream>
#include <cstring>
class Reference
{
std::ostream &d_out;
public:
Reference(std::ostream &out)
:
d_out(out)
{}
void swap(Reference &other)
{
char buffer[sizeof(Reference)];
memcpy(buffer, this, sizeof(Reference));
memcpy(static_cast<void *>(this), &other, sizeof(Reference));
memcpy(static_cast<void *>(&other), buffer,
sizeof(Reference));
}
std::ostream &out()
{
return d_out;
}
};
int main()
{
std::ofstream one{ "one" };
std::ofstream two{ "two" };
Reference ref1{ one }; // ref1/ref2 hold references to
Reference ref2{ two }; // the streams
ref1.out() << "hello to 1\n"; // generate some output
ref2.out() << "hello to 2\n";
ref1.swap(ref2);
ref2.out() << "hello to 1\n"; // more output
ref1.out() << "hello to 2\n";
}
Fast swapping should only be used for self-defined classes for which it can be proven that fast-swapping does not corrupt its objects, when swapped.
Moving information is based on the concept of anonymous (temporary)
data. Temporary values are returned by functions like operator-() and
operator+(Type const &lhs, Type const &rhs), and in general by functions
returning their results `by value' instead of returning references or
pointers.
Anonymous values are always short-lived. When the returned values are
primitive types (int, double, etc.) nothing special happens, but if a
class-type object is returned by value then its destructor can be called
immediately following the function call that produced the value. In any case,
the value itself becomes inaccessible immediately after the call. Of course, a
temporary return value may be bound to a reference (lvalue or rvalue), but as
far as the compiler is concerned the value now has a name, which by itself
ends its status as a temporary value.
In this section we concentrate on anonymous temporary values and show how they can be used to improve the efficiency of object construction and assignment. These special construction and assignment methods are known as move construction and move assignment. Classes supporting move operations are called move-aware.
Classes allocating their own memory usually benefit from becoming move-aware. But a class does not have to use dynamic memory allocation before it can benefit from move operations. Most classes using composition (or inheritance where the base class uses composition) can benefit from move operations as well.
Movable parameters for class Class take the form Class &&tmp. The
parameter is an rvalue reference, and a rvalue reference only binds to an
anonymous temporary value. The compiler is required to call functions offering
movable parameters whenever possible. This happens when the class defines
functions supporting Class && parameters and an anonymous temporary value
is passed to such functions. Once a temporary value has a name (which already
happens inside functions defining Class const & or Class &&tmp
parameters as within such functions the names of these parameters are
available) it is no longer an anonymous temporary value, and within such
functions the compiler no longer calls functions expecting anonymous
temporary values when the parameters are used as arguments.
The next example (using inline member implementations for brevity) illustrates
what happens if a non-const object, a temporary object and a const object are
passed to functions fun for which these kinds of parameters were
defined. Each of these functions call a function gun for which these kinds
of parameters were also defined. The first time fun is called it (as
expected) calls gun(Class &). Then fun(Class &&) is called as its
argument is an anonymous (temporary) object. However, inside fun the
anonymous value has received a name, and so it isn't anonymous
anymore. Consequently, gun(Class &) is called once again. Finally
fun(Class const &) is called, and (as expected) gun(Class const &) is
now called.
#include <iostream>
using namespace std;
class Class
{
public:
Class()
{};
void fun(Class const &other)
{
cout << "fun: Class const &\n";
gun(other);
}
void fun(Class &other)
{
cout << "fun: Class &\n";
gun(other);
}
void fun(Class &&tmp)
{
cout << "fun: Class &&\n";
gun(tmp);
}
void gun(Class const &other)
{
cout << "gun: Class const &\n";
}
void gun(Class &other)
{
cout << "gun: Class &\n";
}
void gun(Class &&tmp)
{
cout << "gun: Class &&\n";
}
};
int main()
{
Class c1;
c1.fun(c1);
c1.fun(Class());
Class const c0;
c1.fun(c0);
}
Generally it is pointless to define a
function having an
rvalue reference return type. The compiler decides whether or not to use
an overloaded member expecting an rvalue reference on the basis of the
provided argument. If it is an anonymous temporary it calls the function
defining the rvalue reference parameter, if such a function is available. An
rvalue reference return type is used, e.g., with the std::move call, to
keep the rvalue reference nature of its argument, which is known to be a
temporary anonymous object. Such a situation can be exploited also in a
situation where a temporary object is passed to (and returned from) a function
which must be able to modify the temporary object. The alternative, passing a
const &, is less attractive as it requires a const_cast before the
object can be modified. Here is an example:
std::string &&doubleString(std::string &&tmp)
{
tmp += tmp;
return std::move(tmp);
}
This allows us to do something like
std::cout << doubleString("hello "s);
to insert hello hello into cout.
The compiler, when selecting a function to call applies a fairly simple algorithm, and also considers copy elision. This is covered shortly (section 9.8).
Strings has, among other members, a data member string
*d_string. Clearly, Strings should define a copy constructor, a
destructor and an overloaded assignment operator.
Now consider the following function loadStrings(std::istream &in)
extracting the strings for a Strings object from in. Next, the
Strings object filled by loadStrings is returned by value. The
function loadStrings returns a temporary object, which can then used to
initialize an external Strings object:
Strings loadStrings(std::istream &in)
{
Strings ret;
// load the strings into 'ret'
return ret;
}
// usage:
Strings store(loadStrings(cin));
In this example two full copies of a Strings object are required:
loadString's value return type from its local
Strings ret object;
store from loadString's return value
Strings class move
constructor:
Strings(Strings &&tmp);
Move constructors of classes using dynamic memory allocation are allowed
to assign the values of pointer data members to their own pointer data members
without requiring them to make copies of the source's data. Next, the
temporary's pointer value is set to zero to prevent its destructor from
destroying data now owned by the just constructed object. The move constructor
has grabbed or
stolen the data from the temporary object. This is
OK as the temporary object cannot be referred to again (as it is anonymous, it
cannot be accessed by other code) and we may assume that the temporary objects
cease to exist shortly after the move-constructor's call. Here is an
implementation of Strings move constructor:
Strings::Strings(Strings &&tmp)
:
d_string(tmp.d_string),
d_size(tmp.d_size),
d_capacity(tmp.d_capacity)
{
tmp.d_string = 0;
tmp.d_capacity = 0;
tmp.d_size = 0;
}
Move construction (in general: moving) must leave the object from which
information was moved in a valid state. It is not specified in what way that
valid state must be realized, but a good rule of thumb is to return the
object to its default constructed state. In the above illustration of a move
constructor tmp.d_size, tmp.d_capacity and tmp.d_string are all set to
0. It's up to the author of the Strings class to decide whether or not
the String's members can all be set to 0. If there's a default constructor
doing exactly that then assigning zeroes is fine. If d_capacity is doubled
once d_size == d_capacity then setting d_capactiy to 1 and letting
d_string point to a newly allocated block of raw memory the size of a
string might be attractive. The source object's capacity might even
remain as-is. E.g., when moving std::string objects the source object's
capacity isn't altered.
In section 9.5 it was stated that the copy constructor is almost always available. Almost always as the declaration of a move constructor suppresses the default availability of the copy constructor. The default copy constructor is also suppressed if a move assignment operator is declared (cf. section 9.7.3).
The following example shows a simple class Class, declaring a move
constructor. In the main function following the class interface a
Class object is defined which is then passed to the constructor of a
second Class object. Compilation fails with the compiler reporting:
error: cannot bind 'Class' lvalue to 'Class&&'
error: initializing argument 1 of 'Class::Class(Class&&)'
class Class
{
public:
Class() = default;
Class(Class &&tmp)
{}
};
int main()
{
Class one;
Class two{ one };
}
The cure is easy: after declaring a (possibly default) copy
constructor the error disappears:
class Class
{
public:
Class() = default;
Class(Class const &other) = default;
Class(Class &&tmp)
{}
};
int main()
{
Class one;
Class two{ one };
}
Move operations cannot be implemented if the class type of a composed data
member does not support moving or copying. Currently, stream classes fall
into this category.
An example of a move-aware class is the class std:string. A class
Person could use composition by defining std::string d_name and
std::string d_address. Its move constructor would then have the following
prototype:
Person(Person &&tmp);
However, the following implementation of this move constructor is incorrect:
Person::Person(Person &&tmp)
:
d_name(tmp.d_name),
d_address(tmp.d_address)
{}
It is incorrect as string's copy constructors rather than
string's move constructors are called. If you're wondering why this
happens then remember that move operations are only performed for
anonymous objects. To the compiler anything having a name isn't anonymous. And
so, by implication, having available a rvalue reference does not mean that
we're referring to an anonymous object. But we know that the move
constructor is only called for anonymous arguments. To use the corresponding
string move operations we have to inform the compiler that we're talking
about anonymous data members as well. For this a cast could be used (e.g.,
static_cast<Person &&>(tmp)), but the C++-0x standard provides the
function
std::move to anonymize a named object. The correct
implementation of Person's move construction is, therefore:
Person::Person(Person &&tmp)
:
d_name( std::move(tmp.d_name) ),
d_address( std::move(tmp.d_address) )
{}
The function std::move is (indirectly) declared by many header
files. If no header is already declaring std::move then include
utility.
When a class using composition not only contains class type data members but also other types of data (pointers, references, primitive data types), then these other data types can be initialized as usual. Primitive data type members can simply be copied; references can be initialized as usual and pointers may use move operations as discussed in the previous section.
The compiler never calls move operations for variables having names. Let's
consider the implications of this by looking at the next example, assuming
the class Class offers a move constructor and a copy constructor:
Class factory();
void fun(Class const &other); // a
void fun(Class &&tmp); // b
void callee(Class &&tmp)
{
fun(tmp); // 1
}
int main()
{
callee(factory());
}
fun's argument is not an anonymous temporary object but a
named temporary object.
fun(tmp) might be called twice the compiler's choice is
understandable. If tmp's data would have been grabbed at the first call,
the second call would receive tmp without any data. But at the last call
we might know that tmp is never used again and so we might like to ensure
that fun(Class &&) is called. For this, once again, std::move is used:
fun(std::move(tmp)); // last call!
Class &operator=(Class &&tmp)
{
swap(tmp);
return *this;
}
If swapping is not supported then the assignment can be performed for each
of the data members in turn, using std::move as shown in the previous
section with a class Person. Here is an example showing how to do this
with that class Person:
Person &operator=(Person &&tmp)
{
d_name = std::move(tmp.d_name);
d_address = std::move(tmp.d_address);
return *this;
}
As noted previously (section 9.7.1) declaring a move assignment
operator suppresses the default availability of the copy constructor. It is
made available again by declaring the copy constructor in the class's
interface (and of course by providing an explicit implementation or by using
the = default default implementation).
Class, supporting swapping through its
swap member. Here is the generic implementation of the overloaded
assignment operator:
Class &operator=(Class const &other)
{
Class tmp{ other };
swap(tmp);
return *this;
}
and this is the move-assignment operator:
Class &operator=(Class &&tmp)
{
swap(tmp);
return *this;
}
They look remarkably similar in the sense that the overloaded assignment
operator's code is identical to the move-assignment operator's code once a
copy of the other object is available. Since the overloaded assignment
operator's tmp object really is nothing but a temporary Class object
we can use this fact by implementing the overloaded assignment operator in
terms of the move-assignment. Here is a second revision of the overloaded
assignment operator:
Class &operator=(Class const &other)
{
Class tmp{ other };
return *this = std::move(tmp);
}
If a class defines pointers to pointer data members there usually is not
only a pointer that is moved, but also a size_t defining the number of
elements in the array of pointers.
Once again, consider the class Strings. Its destructor is implemented
like this:
Strings::~Strings()
{
for (string **end = d_string + d_size; end-- != d_string; )
delete *end;
delete[] d_string;
}
The move constructor (and other move operations!) must realize that the
destructor not only deletes d_string, but also considers d_size. When
d_size and d_string are set to 0, the destructor (correctly) won't
delete anything. In addition, when the class uses
capacity-doubling once d_size ==
d_capacity then the move constructor can still reset the source's
(d_capacity) to 0, since it's known that the tmp object ceases to
exist following the move-assignment:
Strings::Strings(Strings &&tmp)
:
d_string(tmp.d_string),
d_size(tmp.d_size),
d_capacity(tmp.d_capacity)
{
tmp.d_string = 0;
tmp.d_capacity = 0;
tmp.d_size = 0;
}
Other variations are possible as well. The bottom line: the move construcor must ensure that after the destination object has grabbed the source object's data the source object remains in a valid state. That's easily accomplished by assigning the same values to its data members as set by the default constructor.
// assume char *filename
ifstream inStream(openIstream(filename));
For this example to work an ifstream constructor must offer a move
constructor. This ensures that only one object refers to the open istream.
Once classes offer move semantics their objects can also safely be stored in standard containers (cf. chapter 12). When such containers perform reallocations (e.g., when their sizes are enlarged) they use the object's move constructors rather than their copy constructors. As move-only classes suppress copy semantics containers storing objects of move-only classes implement the correct behavior in that it is impossible to assign such containers to each other.
These are the rules the compiler applies when deciding what to provide or not to provide:
= default),
then the default move constructor and move assignment operator are suppressed;
their use is replaced by the corresponding copy operation (constructor or
assignment operator);
If default implementations of copy or move constructors or assignment
operators are suppressed, but they should be available, then it's easy to
provide the default implementations by specifying the required signatures, to
which the specification `= default' is added.
Here is an example of a class offering all defaults: constructor, copy constructor, move constructor, copy assignment operator and move assignment operator:
class Defaults
{
int d_x;
Mov d_mov;
};
Assuming that Mov is a class offering move operations in addition
to the standard copy operations, then the following actions are performed
on the destination's d_mov and d_x:
Defaults factory();
int main()
{ Mov operation: d_x:
---------------------------
Defaults one; Mov(), undefined
Defaults two(one); Mov(Mov const &), one.d_x
Defaults three(factory()); Mov(Mov &&tmp), tmp.d_x
one = two; Mov::operator=( two.d_x
Mov const &),
one = factory(); Mov::operator=( tmp.d_x
Mov &&tmp)
}
If, Defaults declares at least one constructor (not being the copy- or
move constructor) as well as the copy assignment operators then only the
default copy- and declared assignment operator are available. E.g.:
class Defaults
{
int d_x;
Mov d_mov;
public:
Defaults(int x);
Defaults &operator=(Default const &rhs);
};
Defaults factory();
int main()
{ Mov operation: resulting d_x:
--------------------------------
Defaults one; ERROR: not available
Defaults two(one); Mov(Mov const &), one.d_x
Defaults three(factory()); Mov(Mov const &), one.d_x
one = two; Mov::operatpr=( two.d_x
Mov const &)
one = factory(); Mov::operator=( tmp.d_x
Mov const &)
}
To reestablish the defaults, append = default to the appropriate
declarations:
class Defaults
{
int d_x;
Mov d_mov;
public:
Defaults() = default;
Defaults(int x);
// Defaults(Default const &) remains available (by default)
Defaults(Defaults &&tmp) = default;
Defaults &operator=(Defaults const &rhs);
Defaults &operator=(Defaults &&tmp) = default;
};
Be cautious declaring defaults, as default implementations copy data members of primitive types byte-by-byte from the source object to the destination object. This is likely to cause problems with pointer type data members.
The = default suffix can only be used when declaring constructors or
assignment operators in the class's public section.
In the previous sections we've also encountered an important design principle that can be applied to move-aware classes:
Whenever a member of a class receives a const & to an object of its
own class and creates a copy of that object to perform its actual actions on,
then that function's implementation can be implemented by an overloaded
function expecting an rvalue reference.
The former function can now call the latter by passing std::move(tmp)
to it. The advantages of this design principle should be clear: there is only
one implementation of the actual actions, and the class automatically becomes
move-aware with respect to the involved function.
We've seen an initial example of the use of this principle in section 9.7.4. Of course, the principle cannot be applied to the copy constructor itself, as you need a copy constructor to make a copy. The copy- and move constructors must always be implemented independently from each other.
Below two tables are shown. The first table should be used in cases where a function argument has a name, the second table should be used in cases where the argument is anonymous. In each table select the const or non-const column and then use the topmost overloaded function that is available having the specified parameter type.
The tables do not handle functions defining value parameters. If a function has overloads expecting, respectively, a value parameter and some form of reference parameter the compiler reports an ambiguity when such a function is called. In the following selection procedure we may assume, without loss of generality, that this ambiguity does not occur and that all parameter types are reference parameters.
Parameter types matching a function's argument of type T if the argument
is:
| the argument is: | ||
| non-const | const | |
| Use the topmost | (T &) | |
| available function | (T const &) | (T const &) |
int x argument a function fun(int &) is
selected rather than a function fun(int const &). If no fun(int &) is
available the fun(int const &) function is used. If neither is available
(and fun(int) hasn't been defined instead) the compiler reports an error.
| the argument is: | ||
| non-const | const | |
| Use the topmost | (T &&) | |
| available function | (T const &) | (T const &) |
int arg() function is passed
to a function fun for which various overloaded versions are available
fun(int &&) is selected. If this function is unavailable but fun(int
const &) is, then the latter function is used. If none of these two
functions is available the compiler reports an error.
T const & parameter. For anonymous arguments a
similar catch all is available having a higher priority: T const &&
matches all anonymous arguments. Functions having this signature are normally
not defined as their implementations are (should be) identical to the
implementations of the functions expecting a T const & parameter. Since
the temporary can apparently not be modified a function defining a T const
&& parameter has no alternative but to copy the temporary's resources. As
this task is already performed by functions expecting a T const &, there
is no need for implementing functions expecting T const && parameters, and
it's considered bad style if you do.
As we've seen the move constructor grabs the information from a temporary for its own use. That is OK as the temporary is going to be destroyed after that anyway. It also means that the temporary's data members are modified.
Having defined appropriate copy and/or move constructors it may be somewhat surprising to learn that the compiler may decide to stay clear of a copy or move operation. After all making no copy and not moving is more efficient than copying or moving.
The option the compiler has to avoid making copies (or perform move operations) is called copy elision or return value optimization. In all situations where copy or move constructions are appropriate the compiler may apply copy elision. Here are the rules. In sequence the compiler considers the following options, stopping once an option can be selected:
class Elide;
Elide fun() // 1
{
Elide ret;
return ret;
}
void gun(Elide par);
Elide elide(fun()); // 2
gun(fun()); // 3
ret may never exist. Instead of using ret and copying
ret eventually to fun's return value it may directly use the area used
to contain fun's return value.
fun's return value may never exist. Instead of defining an
area containing fun's return value and copying that return value to
elide the compiler may decide to use elide to create fun's return
value in.
par
parameter: fun's return value is directly created in par's area, thus
eliding the copy operation from fun's return value to par.
int,
double and pointers. C++ extends the C-type union concept by offering
unrestricted unions.
Unrestricted unions also allow data fields of types for which non-trivial copy constructors were defined. Such data fields commonly are of class-types. Here is an example of such an unrestricted union:
union Union
{
int u_int;
std::string u_string;
};
One of its fields is defined as a std::string (having a constructor),
turning this union into an unrestricted union. As an unrestricted union
defines at least one field of a type having a constructor the question becomes
how these unions can be constructed and destroyed.
The destructor of a union consisting of, e.g. a std::string and an
int should of course not call the string's destructor if the
union's last (or only) use referred to its int field. Likewise, when
the std::string field is used, and processing switches from the
std::string to the int field, std::string's destructor
should be called before any assignment to the int field takes place.
The compiler does not solve the issue for us, and in fact does not at all implement default constructors or destructors for unrestricted unions. If we try to define an unrestricted union like the one shown above, an error message is issued. E.g.,
error: use of deleted function 'Union::Union()'
error: 'Union::Union()' is implicitly deleted because the default
definition would be ill-formed:
error: union member 'Union::u_string' with non-trivial
'std::basic_string<...>::basic_string() ...'
Consider our unrestricted union's destructor. It clearly should destroy
u_string's data if that is its currently active field; but it should do
nothing if u_int is its currently active field. But how does the
destructor know what field to destroy? It doesn't, as the unrestricted union
contains no information about what field is currently active.
This problem is tackled by embedding the unrestricted union in a larger
aggregate (like a class or a struct) where it becomes a regular data
member. We still consider the unrestricted union a data type by itself, but
its use requires caution. The surrounding class is provided with a d_field
data member keeping track of the currently active union-field. The d_field
value is an enumeration value which is defined by the union. The actual use of
the unrestricted union is completely controlled by the aggregate, freeing the
aggregate's users from any administration related to the unrestricted union.
Using this design we start out with an explicit and empty implementation of the destructor, as there's no way to tell the destructor itself what field to destroy:
Data::Union::~Union()
{};
Nevertheless, unrestricted unions must properly destroy their class-type fields. Since an unrestricted union itself doesn't know what its active field is, it must be informed about that by its surrounding class. To simplify the generalization to other types a static array of pointers to functions destroying the current field's value is used. This array is defined in the union's private section as
static void (Union::*s_destroy[])();
and it is initialized as:
void (Union::*Union::s_destroy[])() =
{
&Union::destroyText,
&Union::destroyValue
};
Primitive data types normally don't need any special attention when they
go out of scope, so destroyValue can be defined as an empty function:
void Union::destroyValue()
{}
On the other hand, the member destroyText must explicitly call
u_text's destructor:
void Union::destroyText()
{
u_text.std::string::~string();
}
Proper destruction can now be realized by a single function void
destroy(Field field) which simply calls the appropriate function:
void Union::destroy(Field type)
{
(this->*s_destroy[type])();
}
Since the unrestricted union is defined as a data member of a surrounding class, the surrounding class's destructor is responsible for the proper destruction of its unrestricted union. As the surrounding class keeps track of the currently active unrestricted union's field its implementation is easy:
Data::~Data()
{
d_union.destroy(d_field);
}
class Data). The class Data is provided with a data member
Union::Field d_field and Data's users might query the currently active
field from, e.g., an accessor field:
class Data
{
Union::Field d_field;
Union d_union;
public:
Data(int value = 0);
Data(Data const &other);
Data(Data &&tmp);
Data(std::string const &text);
~Data(); // empty body
Union::Field field() const;
...
};
Data's constructors receive int or string values. To pass these
values to d_union, we need Union constructors for the various union
fields.
The unrestricted union itself starts out like this:
union Union
{
enum Field
{
TEXT,
VALUE
};
private:
std::string u_text;
int u_value;
public:
Union(Union const &other) = delete;
~Union(); // empty
Union(int value);
Union(std::string const &text);
Union(Union const &other, Field type);
Union(Union &&tmp, Field type);
...
};
The last two Union constructors are comparable to the standard copy-
and move constructors. With unrestricted unions, however, the existing union's
actual type needs to be specified so that the correct field is initialized.
To simplify the generalization to other types we apply a procedure that is
comparable to the procedure we followed for destroying an understricted union:
we define a static array of pointers to copy-functions. This array is declared
in the union's private section as
static void (Union::*s_copy[])(Union const &other);
and it is defined as:
void (Union::*Union::s_copy[])(Union const &other) =
{
&Union::copyText,
&Union::copyValue
};
The copyText and copyValue private members are responsible for
copying other's data fields. However, there is a little snag. Although
basic types can directly be assigned, class-type fields cannot. Destination
fields cannot be initialized using member initializers as the field to
initialize depends on the Field type that's passed to the
constructor. Because of that the initialization must be performed inside the
constructors' bodies. At that point the data fields are
merely a series of uninitialized bytes, and so placement new is used to
copy-construct class-type fields. Here are the implementations of the copy
functions:
void Union::copyValue(Union const &other)
{
u_value = other.u_value;
}
void Union::copyText(Union const &other)
{
new(&u_text) string{ other.u_text };
}
When implementing the union's move constructor other considerations must be
taken into account. Since we're free to do whatever we want with the move
constructor's Union &&tmp object, we can simply grab its current field,
and store a VALUE type of value into tmp. For that we use the
Union's swap facility, the current object's field, another Union
object, and the other Union's field type (swapping is discussed in the
next section). Of course, if there isn't any primitive typed field this
doesn't work. In that case field-specific move functions must be used,
comparable to the ones used when copy-constructing a Union object.
Now we're ready for the constructors' implementations:
Union::Union(std::string const &text)
:
u_text(text)
{}
Union::Union(int value)
:
u_value(value)
{}
Union::Union(Union &&tmp, Field type)
{
swap(VALUE, tmp, type);
}
Union::Union(Union const &other, Field type)
{
(this->*s_copy[type])(other);
}
Data::Data(Data const &other)
:
d_field(other.d_field),
d_union(other.d_union, d_field)
{}
Data::Data(int value)
:
d_field(Union::VALUE),
d_union(value)
{}
Data::Data(Data const &other)
:
d_field(other.d_field),
d_union(other.d_union, d_field)
{}
swap member. It needs
three arguments: the current object's field, another union object, and that
union's field. The prototype of our unrestricted union's swap member,
therefore, is:
void swap(Field current, Union &other, Field next);
To implement it similar considerations as encountered with the copy
constructor apply. An unrestricted union having k fields must support k
* k different swap situations. Representing these in a k * k matrix we
note that the diagonal elements refer to swapping identical elements for which
no special considerations apply (assuming swapping of identical data types is
supported). The lower-triangle elements are identical to their transposed
upper-triangle elements, and so they can use those elements after reverting
the current and other union objects. All field-specific swap functions can be
organized in a k x k static matrix of pointers to swapping members. For
Union the declaration of that matrix is
static void (Union::*s_swap[][2])(Union &other);
and its definition is
void (Union::*Union::s_swap[][2])(Union &other) =
{
{ &Union::swap2Text, &Union::swapTextValue},
{ &Union::swapValueText, &Union::swap2Value},
};
The diagonal and lower-triangle elements are straightforwardly implemented. E.g.,
void Union::swap2Text(Union &other)
{
u_text.swap(other.u_text);
}
void Union::swapValueText(Union &other)
{
other.swapTextValue(*this);
}
but implementing the upper-triangle elements requires some thought. To
install a class-type field placement new must again be used. But this time
we're not copying but moving, as the current object is going to lose its
content. Like swapping, moving should always succeed. Following the move
construction the other object has received the current object's data. As the
current object keeps its valid state after the move, it must also explicitly
be destroyed to properly end its lifetime. Here is the implementation of
swapTextValue:
void Union::swapTextValue(Union &other)
{
int value = other.u_value; // save the int value
// install string at other
new(&other.u_text) string{ std::move(u_text) };
u_text.~string(); // remove the old field's union
u_value = value; // store current's new value
}
When an unrestricted union has multiple class-type fields then when
swapping move construction must be applied to both unrestricted unions. This
requires a temporary. Assume an unrestricted union supports fields of classes
This and That then to swap unrestricted unions using, respectively the
This and That fields we do as follows:
void ThisThat::swapThisThat(ThisThat &other)
{
This tmp{ std::move(u_this) }; // save the current object
u_this.~This(); // properly destroy it
// install the other object at
// this object
new(&u_that) That{ std::move(other.u_that) };
other.u_that.~That(); // properly destroy the other
// object
// install this object's original
// value at the other object
new(&other.u_this) This{ std::move(tmp) };
} // tmp is automatically destroyed
Now that unrestricted unions can be swapped, their swap member can be
used by swap members of surrounding classes. E.g.,
void Data::swap(Data &other)
{
d_union.swap(d_field, other.d_union, other.d_field);
Union::Field field = d_field; // swap the fields
d_field = other.d_field;
other.d_field = field;
}
Data object to another one: copy assignment
and move assignment. Their implementations are standard:
Data &Data::operator=(Data const &other) // copy-assignment
{
Data tmp{ other };
swap(tmp);
return *this;
}
Data &Data::operator=(Data &&tmp) // move-assignment
{
swap(tmp);
return *this;
}
Since swap has already been defined the assignment operators need no
further attention: they are implemented using their standard implementations.
When unrestricted unions are used outside of surrounding classes a
situation may arise where two unrestricted unions are directly assigned to
each other. In that case the unions' active fields must somehow be
available. Since operator= can only be defined having one parameter,
simply passing an unrestricted union as its rvalue would lack information
about the lvalue's and rvalue's active fields. Instead two members are
suggested: copy, doing copy assignment and move, doing move
assignment. Their implementations closely resemble those of the standard
assignment operators:
void Union::copy(Field type, Union const &other, Field next)
{
Union tmp{ other, next }; // create a copy
swap(type, tmp, next); // swap *this and tmp
tmp.destroy(type); // destroy tmp
}
void Union::move(Field type, Union &&tmp, Field next)
{
swap(type, tmp, next);
}
In the source distribution you'll find a directory
yo/memory/examples/unions. It contains a small demo-program in which
Union and Data are used.
double, a bool and std::string these three different data types
may be aggregated using a struct that merely exists to pass along
values. Data protection and functionality is hardly ever an issue. For such
cases C and C++ use structs. But as a C++ struct is just a
class with special access rights some members (constructors, destructor,
overloaded assignment operator) may implicitly be defined. Aggregates
capitalize on this concept by requiring that their definitions remain as
simple as possible, showing the following characteristics:
Aggregates can also be arrays, in which case the array elements are the
aggregate's elements. If an aggregate is a struct its direct base classes
are its elements (if any), followed by the struct's data members, in their
declaration order. Here is an example:
struct Outer
{
struct Inner
{
int d_int;
double d_double;
};
std::string d_string;
Inner d_inner;
};
Outer out{ "hello", { 1, 12.5} };
Outer out's d_string is initialized with hello", its d_inner
member has two data members: d_int is initialized to 1, d_double to
12.5.
(Designated) initializer lists can also be used (cf. section 3.3.5). Also, often structured binding declarations (cf. section 3.3.7.1) can be used to avoid explicitly defining an aggregate data type.
Classes having pointer data members, pointing to dynamically allocated memory controlled by the objects of those classes, are potential sources of memory leaks. The extensions introduced in this chapter implement the standard defense against such memory leaks.
Encapsulation (data hiding) allows us to ensure that the object's data integrity is maintained. The automatic activation of constructors and destructors greatly enhance our capabilities to ensure the data integrity of objects doing dynamic memory allocation.
A simple conclusion is therefore that classes whose objects allocate memory controlled by themselves must at least implement a destructor, an overloaded assignment operator and a copy constructor. Implementing a move constructor remains optional, but it allows us to use factory functions with classes not allowing copy construction and/or assignment.
In the end, assuming the availability of at least a copy or move constructor, the compiler might avoid them using copy elision. The compiler is free to use copy elision wherever possible; it is, however, never a requirement. The compiler may therefore always decide not to use copy elision. In all situations where otherwise a copy or move constructor would have been used the compiler may consider to use copy elision.